Trong thế giới toàn cầu hóa ngày nay, phục vụ cho các ngôn ngữ và nền văn hóa đa dạng là điều cần thiết để truy xuất và phân tích thông tin hiệu quả. Ngôn ngữ Nhật Bản rất phong phú và phức tạp, đặt ra những thách thức độc đáo cho việc phân tích văn bản. Ngôn ngữ Nhật Bản rất phong phú và phức tạp, đặt ra những thách thức độc đáo cho việc phân tích văn bản. Trình phân tích tiếng Nhật (Japanese Analyzer) của Elastic Search đã ra đời để đảm bảo lập chỉ mục chính xác, tìm kiếm hiệu quả và xử lý ngôn ngữ chính xác. Tìm hiểu ngay về cách thức hoạt động của Japanese Analyzer và tận dụng các tính năng để nâng cao việc triển khai Elasticsearch!

Hiểu về Elasticsearch Japanese analyzer
Cốt lõi của Elasticsearch Japanese analyzer là công cụ phân tích hình thái Kuromoji mạnh mẽ
Kuromoji vượt trội trong việc mã hóa văn bản tiếng Nhật, chia nó thành các đơn vị có ý nghĩa được gọi là token, hiểu vai trò ngữ pháp của chúng và cung cấp thông tin chuyên sâu về ngôn ngữ như gắn thẻ một phần của bài phát biểu, trích xuất dạng cơ bản của token (base form) và đọc cách phát âm.
Các bạn có thể thử công cụ phân tích Kuromoji ở đây. Hãy copy một câu tiếng Nhật trên Google dịch, paste vào và bấm Tokenize.
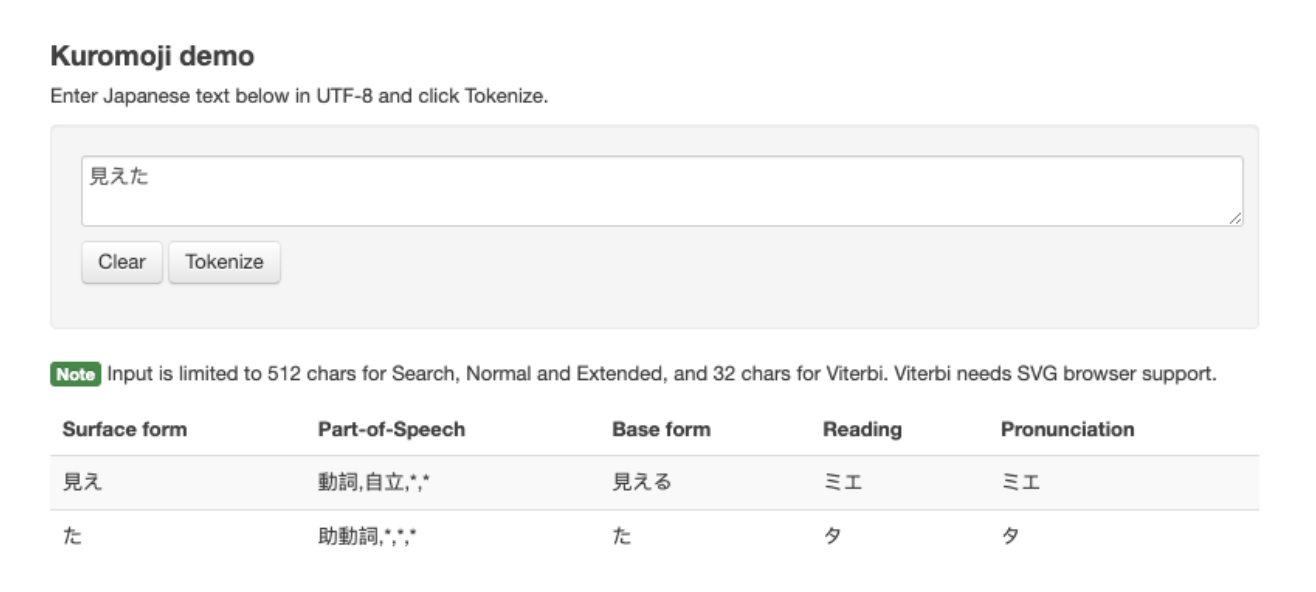
Như mình đã thử, các bạn có thể thấy câu tiếng Nhật mình nhập vào (見えた nghĩa là đã thấy) đã được tách ra làm 2 token, gồm các thành phần:
- Surface form: Nguyên bản từ mà các bạn nhập vào là 見え và た.
- Part-of-Speech: Loại từ gì, nôm na rằng đây là động từ, danh từ hay gì đó,…
- Base form: Thứ quan trọng nhất, dạng cơ bản của từ. 見え có dạng cơ bản là 見える và た thì dạng cơ bản vẫn là た.
- Reading: Cách đọc ミエタ mi-e-ta
- Pronunciation: Cách phát âm ミエタ mi-e-ta
Dù không hiểu nhiều về tiếng Nhật, nhưng như tra cứu từ điển vậy, khi nhập vào một câu tiếng Nhật, Kuromoji trả về cho ta các token với dạng base form của token đó. Và đó cũng là cách cơ bản để Elasticsearch Japanese Analyzer thực hiện việc phân tích tiếng Nhật.
Tính năng của Elasticsearch Japanese analyzer
Cơ bản
Là một analyzer trong Elasticsearch, Japanese analyzer cũng có 2 thành phần cơ bản:
- Tokenizer: Chịu trách nhiệm tách văn bản thành các token. Elasticsearch cung cấp cho ta một tokenizer chuyên dụng cho tiếng Nhật là
kuromoji_tokenizer. Bản chất là sử dụng Kuromoji để tách văn bản thành các token (surface form) như mình đã thử ở trên. - Filter: Chịu trách nhiệm biến đổi các token về dạng dễ tìm kiếm nhất (thông thường sẽ biến đổi lowercase). Elasticsearch cung cấp một filter chuyên dụng cho tiếng Nhật là
kuromoji_stemmer. Bản chất là biến đổi các token từ dạng surface form về dạng base form.
Tóm tắt lại, đầu vào của analyzer là một văn bản, đầu ra sẽ là các token được tách và biển đổi từ văn bản đó. Và những gì Japanese analyzer cho ra chính là các token dạng base form mà ta có thể dễ dàng lấy được từ trang Kuromoji demo bên trên.
Dictionary và Synonym
Ngoài ra, Elasticsearch cung cấp cho chúng ta khả năng tự custom, thêm thắt tokenizer và filter theo chủ đích của mình bằng cách thêm vào các file dictionary và synonym mà ta tự viết.
Dictionary
Là một file text, mỗi dòng có cú pháp là text,tokens,readings,part-of-speech
- Text: Từ ghép hoặc cụm từ xuất hiện trong nội dung của bạn.
- Tokens: Đây chính là các token được trả về, được viết cách nhau bởi khoảng trắng
- Reading: chứa cùng một văn bản như token với bất kỳ chữ kanji nào được thay thế bằng katakana. Điều này mô tả cách phát âm của các mã thông báo
- Part-of-speech: xác định văn bản là gì, ví dụ như một danh từ hoặc động từ.
Khi phát hiện ra đoạn text mà bạn đã quy định, nó sẽ trả về các token mà bạn muốn.
Synonym
Là một file text, mỗi dòng là định nghĩa một tập hợp các từ đồng nghĩa với nhau, cách nhau bởi dấu phẩy.
Khi token được tìm thấy trong file này, Elasticsearch sẽ trả về tất cả các từ nằm cùng dòng với token đó.
Thực hành
Hãy cùng thực hành để hiểu rõ hơn về các nội dung trên nhé! Mình sẽ sử dụng Docker để cài đặt Elasticsearch.
Khởi tạo
Tạo project mới:
mkdir elasticsearch_analyzer_practice
cd elasticsearch_analyzer_practiceTạo 2 file khai báo dictionary và synonym
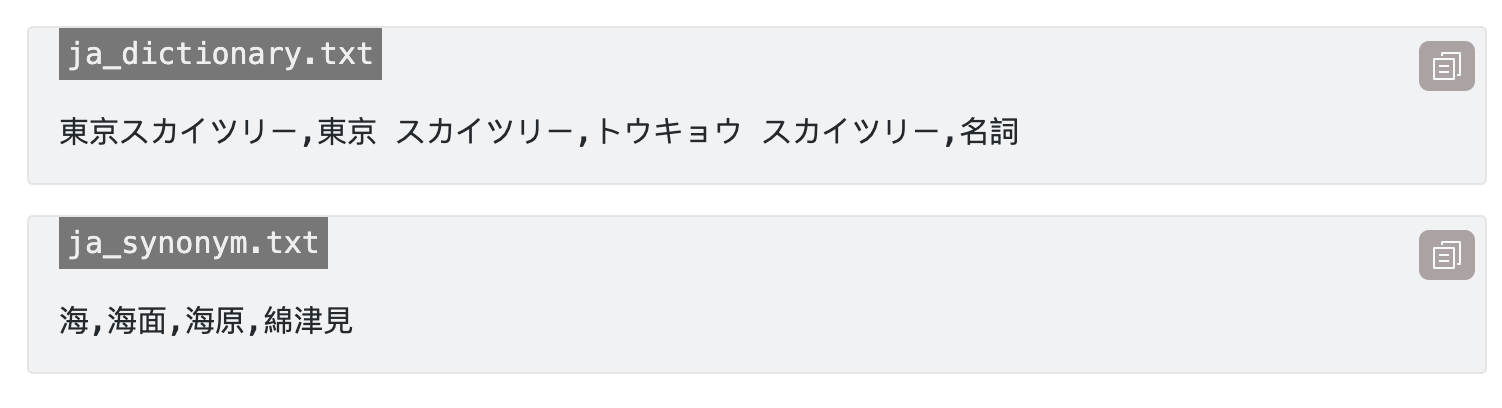
Tạo Dockerfile như sau:
FROM docker.elastic.co/elasticsearch/elasticsearch:7.17.7
RUN elasticsearch-plugin install analysis-kuromoji
COPY ja_synonym.txt /usr/share/elasticsearch/config/ja_synonym.txt
COPY ja_dictionary.txt /usr/share/elasticsearch/config/ja_dictionary.txt
Trong này, mình sử dụng Elasticsearch 7.17.7 và cài đặt plugin analysis-kuromoji.
Copy 2 file ja_synonym.txt và ja_dictionary.txt vào folder config.
Tạo docker-compose file:

Trong file compose, mình chạy 2 service là elasticsearch ở cổng 9200 và Kibana ở cổng 5601.
Mình sẽ sử dụng console Kibana để thao tác với Elasticsearch dễ dàng hơn.
Sau đó chạy docker-compose:
docker-compose up --buildChạy thử
Sử dụng Kibana console ở đường dẫn http://localhost:5601/app/dev_tools#/console
Đầu tiên là tạo Index:

Hãy xem mình đã setting gì cho Index này nhé:
- Khai báo 1 filter tên là
ja_synonymsử dụng fileja_synonym.txt. - Khai báo 2 tokenizer là
ja_tokenizerchỉ sử dụng Kuromoji vàja_tokenizer_customcó sử dụng cả fileja_dictionary.txt. - Khai báo 3 analyzer:
ja_analyzersử dụng Kuromoji mặc định.ja_analyzer_dictionarysử dụng thêm dictionary.ja_analyzer_synonymsử dụng thêm filter synonym.
Giờ hãy xem các analyzer hoạt động như nào nhé.
Analyzer chỉ sử dụng Kuromoji cơ bản
GET /demo/_analyze
{
"analyzer" : "ja_analyzer",
"text" : "東京スカイツリー"
}
Kết quả:

イツリー thành 3 token 東京, スカイ và ツリー đúng theo từ điển Kuromoji.
Analyzer có thêm dictionary
GET /demo/_analyze
{
"analyzer" : "ja_analyzer_dictionary",
"text" : "東京スカイツリー"
}
Kết quả:

Analyzer ja_analyzer_custom chỉ tách text 東京スカイツリー thành 2 token 東京 và スカイツリ. Lý do vì mình đã quy định text này trong file dictionary.txt.
Analyzer có thêm synonym
GET /demo/_analyze
{
"analyzer" : "ja_analyzer_synonym",
"text" : "海面"
}
Kết quả:

Kết quả được tách thành rất nhiều token do anazyler ja_analyzer_synonym có sử dụng synonym mà mình đã quy định cho từ 海面.
Tiểu kết
Như vậy, chúng ta đã vừa cùng tìm hiểu về trình phân tích tiếng Nhật (Japanese analyzer) của Elasticsearch. Tôi hy vọng bài viết trên sẽ hữu ích đối với các bạn. Nếu có comment gì, hãy chia sẻ cùng chúng tôi nhé!
Tác giả: Trương Tiến Đạt
Tìm hiểu thêm về PIXTA Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Fanpage: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/