
Giới thiệu chung
Với sự phát triển mạnh mẽ của mô hình deep learning trong những năm gần đây, các mạng tích chập đã phát triển, đạt được độ chính xác và hiệu suất cao trong nhiều bài toán ứng dụng mảng thị giác máy tính như phân loại đối tượng (object classification), phân vùng đối tượng (semantic/instance segmentation) và nhận diện đối tượng (object detection), … khiến các mô hình deep learning này có một bước tiến vượt bậc so với các phương pháp truyền thống trước đó.
Đặc biệt nói về bài toán object detection, các mô hình deep learning theo mảng này đã trở thành một trong ứng dụng thực tiễn quan trọng, như video security/surveillance, augmented reality, autonomous navigation, face detection, self-checkout convenience store, … Một số mô hình object detection nổi tiếng thường thấy như Faster-RCNN, You Only Look Once (YOLO) hay Single Shot Multibox Detector (SSD) đã đạt được kết quả ấn tượng cả về mặt thời gian và hiệu quả.
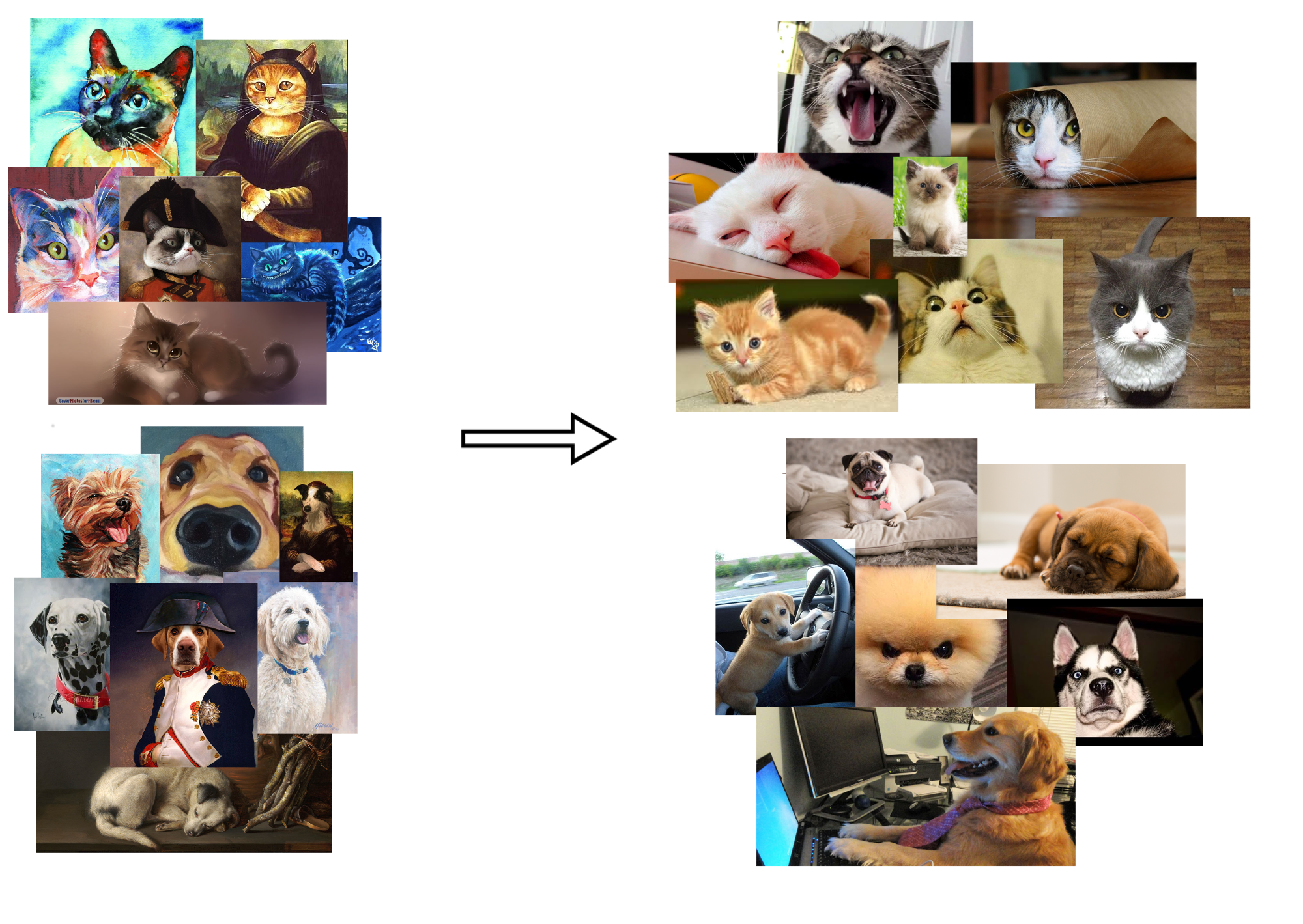
Fig.1. Hai domain dataset khác nhau nhưng có cùng loại đối tượng (chó, mèo) và mục tiêu dự đoán. Phải, chó mèo trên thực tế. Trái, chó mèo theo phong cách hoạt hình

(a) Cityscapes → FoggyCityscapes – – – – – – – – – – – – – – – – – – – (b) Visible → Thermal

(c) Rome → Tokyo – – – – – – – – – – – – – – – – – – – – – – – (d) Synthetic → Real

Fig.2. Trực quan hóa kết quả của mô hình nhận diện đối tượng. Trái: Mô hình huấn luyện trên tập source hoạt động trên tập source, Phải: Mô hình huấn luyện trên tập source hoạt động trên tập target
Tuy nhiên, việc tạo ra được một mô hình deep learning tốt phụ thuộc rất nhiều vào số lượng và chất lượng dữ liệu. Một nhược điểm lớn đáng chú ý nữa của các mô hình deep learning là tính phổ quát (generalization) kém, cùng một mục tiêu nhưng với một ảnh có tính đặc trưng chưa từng xuất hiện ở tập huấn luyện (góc nhìn, độ sáng, tính chất, môi trường, số lượng đối tượng, loại đối tượng, …), có sự khác nhau lớn về thông tin style và context, mô hình sẽ hoạt động khá tệ.
Ví dụ: Mô hình huấn luyện từ dữ liệu ảnh từ Rome hoạt động trên ảnh từ Tokyo (fig.1(c)), ảnh sunny hoạt động trên ảnh foggy (fig.1(a)), ảnh màu hoạt động trên ảnh nhiệt (fig.1(b)), ảnh giả lập hoạt động trên ảnh thực (fig.1(d)), … Vấn đề khi mô hình được huấn luyện trên một tập dữ liệu cụ thể (source dataset) không thể tổng quát hóa trên tập dữ liệu có phân phối khác (target dataset) được gọi là domain shift hoặc distribution shift.
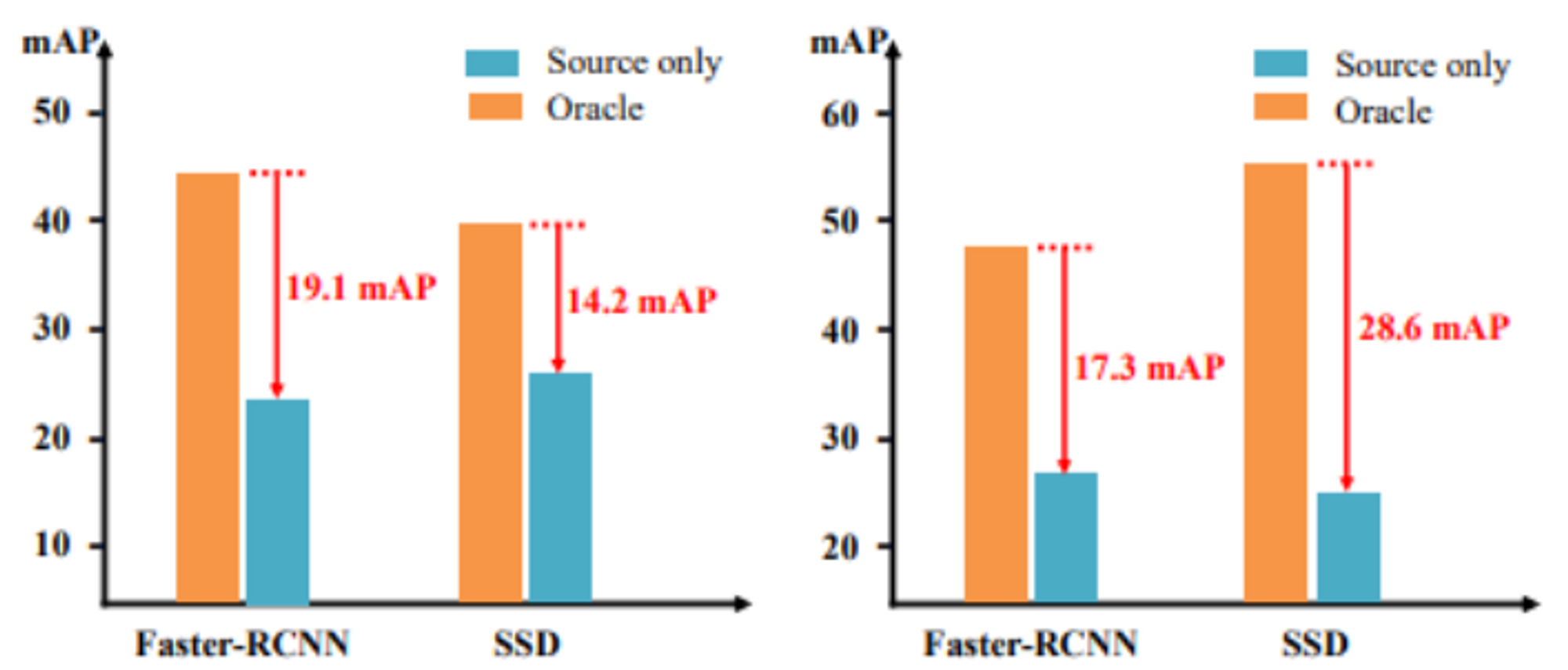
(a) Cityscapes → FoggyCityscapes – – – – – – – – – – – – – – – – – – – (b) Pascal VOC → Clipart
Fig. 3. Trực quan hóa hiệu năng của mô hình. Chúng ta có thể nhận thấy sự giảm hiệu năng rõ rệt khi xuất hiện domain shift giữa tập source và tập target
Giải pháp đơn giản và trực quan nhất là ngồi dán nhãn đối tượng cho toàn bộ dữ liệu trong tập target (:v), nhưng có vẻ điều này là không phù hợp và gặp rất nhiều khó khăn trong thực tế khi đối với một bộ dữ liệu nhất định, chi phí nhân công và thời gian cực kì lớn tùy vào số lượng và yêu cầu của thông tin dữ liệu, chưa kể tới việc cách thức dán nhãn của từng người là không hoàn toàn giống nhau, nếu yêu cầu dán quá cầu kì hay đối tượng bị che khuất, làm mờ hoặc đồng thời xuất hiện sát gần nhau, nhãn cho dữ liệu đó sẽ bị trừu tượng hóa và bị thay đổi tùy vào người dán.
Các bài toán thích ứng miền không giám sát (unsupervised domain adaptation – UDA) đã được sinh ra để giải quyết những vấn đề này. Với sự phát triển của dữ liệu lớn (big data) và phần cứng, hướng đi này ngày càng nhận được rất nhiều sự quan tâm từ cộng đồng, với mục đích làm mô hình học được tính tổng quát hóa giữa các miền (domain), từ source domain có nhãn đầy đủ sang target domain có nhãn thô mà không tốn quá nhiều chi phí để dán nhãn.
Hay nói cách khác, Domain Adaptation là quá trình học Invariance features (đặc trưng invariance).
Vậy “Invariance features” là gì?
Nói một cách thô và trừu tượng thì invariance features là đặc trưng của đối tượng mà nó sẽ không đổi kể cả đối tượng đó nằm ở hoàn cảnh khác.
Nghe có vẻ hiển nhiên nhưng khá khó hiểu đúng không?
Ví dụ bạn có 2 ảnh chụp 2 con mèo khác nhau, một con nằm ở ngoài trời và một con nằm ở trong nhà, hiển nhiên bạn sẽ nhận ra rõ 2 con mèo và dễ dàng phân biệt được chúng với môi trường xung quanh. Nhưng đối với máy tính, chưa chắc có thể hoàn toàn phân biệt được như vậy, có thể nó sẽ nhận ra con mèo nhưng phần nào phụ thuộc vào môi trường xung quanh tùy thuộc vào dữ liệu nó được học.

Fig. 4. Tập dữ liệu chó mèo. Trong đó, toàn bộ ảnh mèo đều nằm trong nhà và toàn bộ ảnh chó đều chơi ngoài trời
Xét trường hợp cụ thể hơn nhé! Giả sử bạn có một bộ dữ liệu về chó mèo và điều đặc biệt của nó là toàn bộ ảnh chứa mèo đều nằm trong nhà và toàn bộ ảnh chứa chó đều chơi ở ngoài trời. Vậy sau khi huấn luyện, với ảnh con mèo đang chơi ngoài trời và ảnh con chó đang nằm trong nhà thì mô hình sẽ dự đoán ra kết quả như thế nào?
Vì đầu vào mô hình luôn là các con số nên tất nhiên nó cũng chả thể lấy các nhãn “dog” và “cat” vào để huấn luyện được, mà phải thông qua biến đổi về nhãn số là “0” và “1”, nên chúng sẽ không thật sự hiểu nhiệm vụ huấn luyện của mình là gì. Tất nhiên sẽ có mô hình học tốt, dự đoán đúng chính xác là “chó” và “mèo” nhưng nếu trong trường hợp khác, mô hình lại dự đoán thành “trong nhà” và “ngoài trời” thì sao? Về mặt kết quả thì là sai nhưng đối với mô hình, nó phải “make sense” đúng không ạ?
Đó chính là sự khó khăn khi học invariance features cho bộ dữ liệu.
Và đây mới chỉ do ảnh hưởng từ style features (trong nhà và ngoài trời), nếu là trong bài toán object detection, sự khác nhau của phân phối về kích thước đối tượng, vị trí và số lượng của chúng (như hình dưới là ví dụ) khiến cho việc huấn luyện mô hình để học được invariance features sẽ phức tạp và khó khăn hơn rất nhiều.
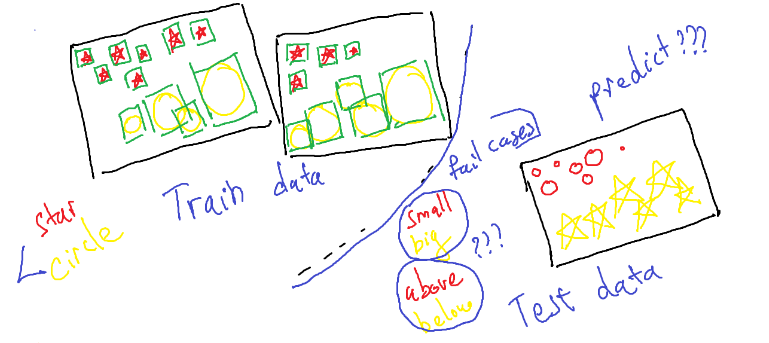
Fig. 5. Dữ liệu object detection về “hình sao đỏ” và “hình tròn vàng”. Trong đó, “hình sao đỏ” khá nhỏ và luôn nằm ở trên, “hình tròn vàng” có kích thước to và luôn nằm ở dưới. Vậy khi dự đoán cho sample mới ở test data, các “fail cases” có thể xảy ra là gì?
Đây cũng là lí do mà các pre-trained lớn cho bộ dữ liệu phổ biến cụ thể không thể sử dụng lại 100% cho bộ dữ liệu yêu cầu có cùng mục tiêu nhưng khác môi trường được.
Khi các mô hình classification, segmentation đã được nghiên cứu và giải quyết tốt phần nào vấn đề này thì object detection vẫn đang tiếp tục được nghiên cứu và khó khăn vì nhiều hạn chế đặc thù. Không như classification (image-level prediction) và segmentation (pixel-level prediction) thì object detection (instance-level prediction) có liên quan đến cả thông tin vùng đối tượng (object localization) và thông phân loại đối tượng (object category), việc chuyển giao kiến thức giữa các domain đồng thời tối ưu 2 luồng thông tin này là một thử thách khá lớn hiện nay. Trong bài viết này, chúng ta sẽ tập trung về các phương pháp Unsupervised Domain Adaptation (UDA).
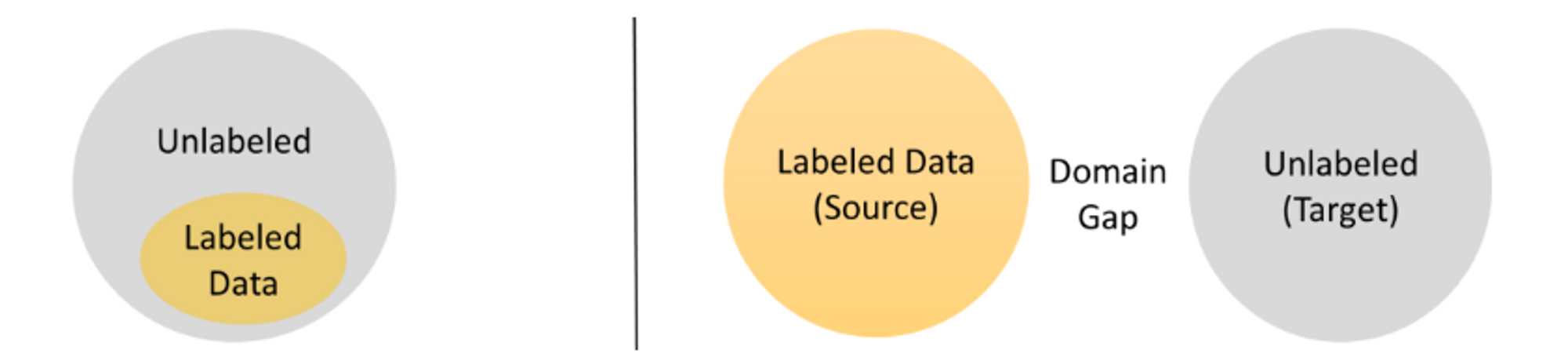
Fig. 6. So sánh 2 phương pháp SSL và UDA. Trong UDA, 2 dữ liệu domain không nằm trong cùng một phân phối (thường xảy ra trong thực tế) so với SSL
Domain Adaptation được chia ra làm 4 hướng đi chủ yếu:
| Semi-supervised | Weakly-supervised | Unsupervised | Unsupervised without source domain | |
|---|---|---|---|---|
| Source domain | Full annotations | Full annotations | Full annotations | No data (but has pretrained) |
| Target domain | Parts of annotation | Full Weakly annotations | No annotations | No annotations |
Weakly annotation: Hiểu đơn giản là dữ liệu được label một cách đơn giản, không có thông tin các bounding boxes (ví dụ như cho biết trong hình có những đối tượng nào hoặc cho biết vị trí đối tượng đó nhưng không cho biết thông tin bounding boxes cụ thể)
Một số phương pháp thường dùng
Vì hướng nghiên cứu này là chưa nhiều (ít nhất là với nghiên cứu áp dụng deep learning) mà số lượng domain nghiên cứu nhỏ trong nó là nhiều nhưng khá rời rạc nên tôi sẽ chỉ nói về 3 phương pháp lớn mà hầu hết các nghiên cứu của domain adaptations đều sử dụng.
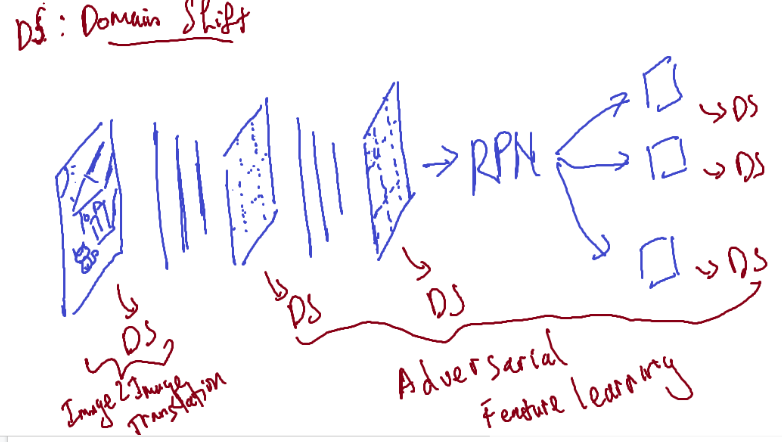
Fig. 7. Quy trình forward của mô hình trong quá trình huấn luyện, nhìn chung khá giống với các mô hình object detection bình thường nhưng sẽ có thêm các nhánh domain shift
Như đã đề cập từ trước, mục đích chung của hướng nghiên cứu lớn này là giảm domain shift và theo hình trên, ta có thể giảm domain shift tại nhiều features trong quá trình forward của mô hình. Tùy theo vị trí mong muốn để giảm, ta sẽ có các phương pháp sau:
- Phương pháp giảm domain shift tại các feature maps là Adversarial Feature Learning.
- Phương pháp giảm domain shift ngay tại vị trí ban đầu (ảnh trước khi đưa vào mô hình) là Image-to-image translation.
- Phương pháp cuối cùng không giống 2 phương pháp trên nhưng bạn có thể gặp khá nhiều trong các cuộc thi như Kaggle, đó là Pseudo-label based self-learning.
Adversarial Feature Learning
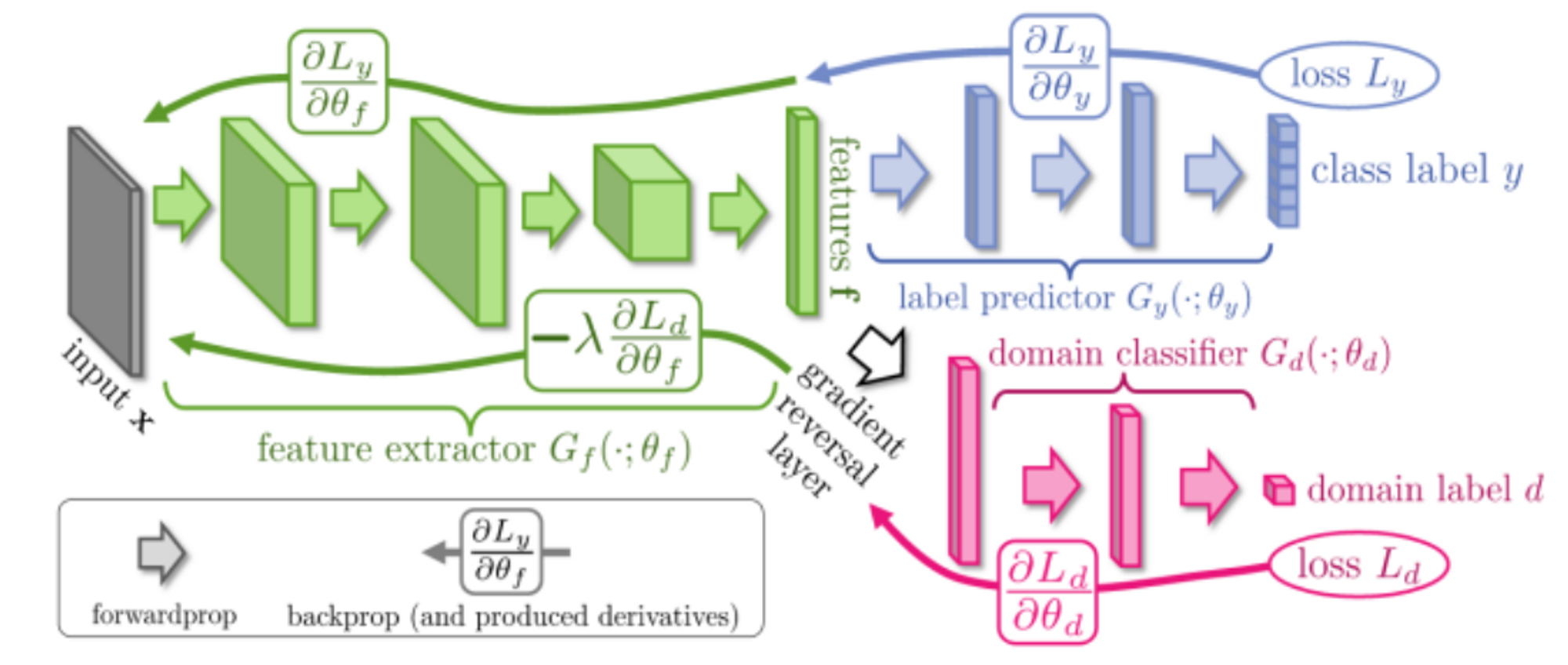
Fig. 8. Trực quan mô hình GRL cho adversarial learning
Ứng dụng kỹ thuật phân biệt miền (domain discriminator) trong huấn luyện học đối đầu (adversarial learning) đối với các mô hình object detection, kỹ thuật domain discriminator thường dùng là gradient reversal layer (GRL) dựa trên việc huấn luyện đặc trưng.
Ý tưởng của kỹ thuật này giống với strategy learning, gồm 2 đầu huấn luyện (hoặc gọi là agent): detector model được huấn luyện nhằm tạo ra các đặc trưng của 2 domain sao cho domain discriminator không phân biệt được đặc trưng thuộc domain nào. Đồng thời Domain discriminator cũng được huấn luyện nhằm phân biệt được các đặc trưng tạo ra từ detector model thuộc domain nào.
Còn về mặt chứng minh toán học cụ thể, các bạn có thể đọc thêm tại đây.
Lý thuyết phức tạp là vậy nhưng trong code, theo như hình, ta sẽ có 2 head, một head có nhiệm vụ dự đoán thông thường của bài toán (categories classification, object detection, …) và một head đóng vai trò là domain discriminator, khi áp dụng backward tại nhánh head này thì chúng ta chỉ đơn giản là đảo ngược dấu (nhân với −1) khi backward là được:
class GradReverse(torch.autograd.Function):
def forward(self, x):
return x.view_as(x)
def backward(self, grad_output):
return (grad_output * -1)
Ta có thể thấy kỹ thuật này khá tương đồng với các mô hình sinh (GAN), việc học đối lập tạo được các domain invariant features trong khi vẫn có khả năng phân biệt được đối tượng của 2 domain.
Cũng vì là mô hình học đối lập tương tự GAN, mô hình GRL có quá trình huấn luyện và cập nhật tham số bất ổn định. Đó cũng là điểm yếu lớn nhất của phương pháp này (có thể đọc thêm ví dụ chứng minh tính bất ổn tương tự GAN tại đây và tính bất ổn trong quá trình huấn luyện tại đây) .
Image-to-image translation

Fig. 9. Ảnh source domain (trái) và ảnh target-like source domain (phải)
Từ các cặp ảnh từ 2 domain, chúng ta sẽ dùng các mô hình translation như style transfer, GAN, … để biến đổi ảnh target sang ảnh source-like và ngược lại.
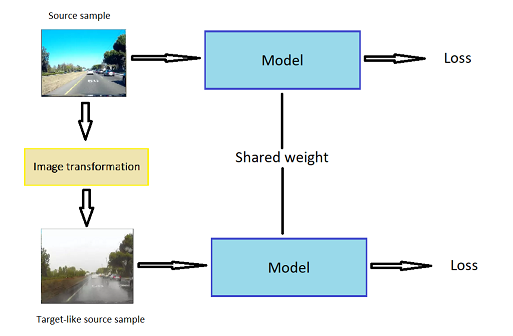
Fig. 10. chuyển giao domain trong ảnh. Ảnh source domain (trên) đi qua mô hình để tạo ra ảnh source domain nhưng chứa đặc trưng về style của target domain (dưới)
Kỹ thuật này sẽ làm giảm domain shift giữa 2 phân phối dữ liệu, khiến mô hình dễ dàng học một cách tổng quát hơn.
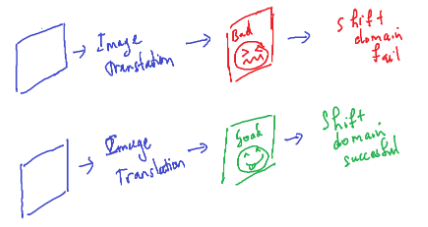
Fig. 11. Domain shift theo Image-to-image translation phụ thuộc khá nhiều vào mô hình image translation để quyết định xem kết quả shift có tốt hay không
Tuy nhiên, phương pháp này phụ thuộc rất nhiều vào mô hình translation phải tốt. Điều này là khó, vì việc huấn luyện một mô hình translation trở nên hoàn hảo tốn cực kỳ nhiều dữ liệu cũng như tài nguyên, công sức, chưa kể các metrics đánh giá hiện giờ không hoàn toàn quyết định được một mô hình translation có thể gọi là tốt được hay không.
Pseudo-label based self-learning
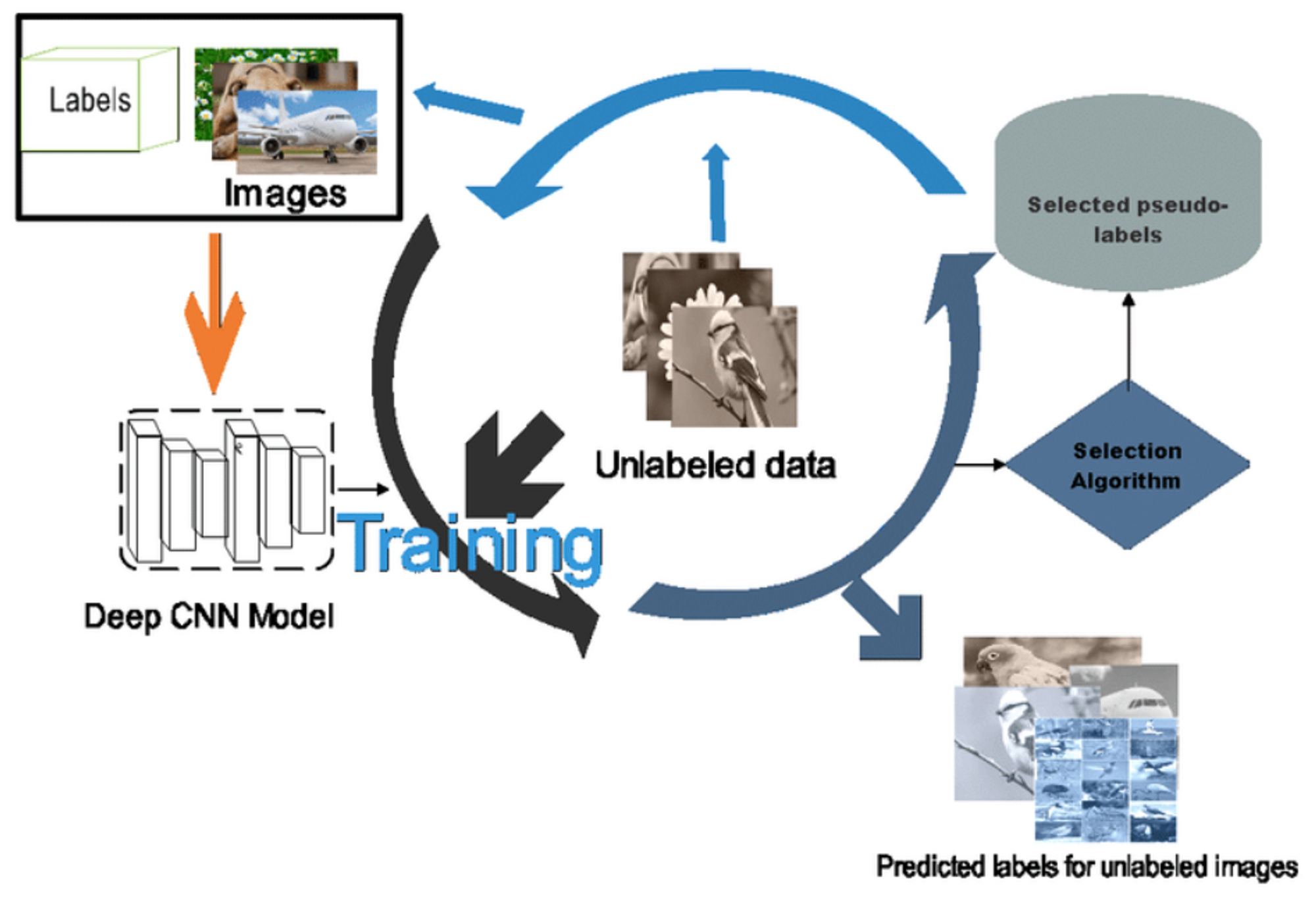
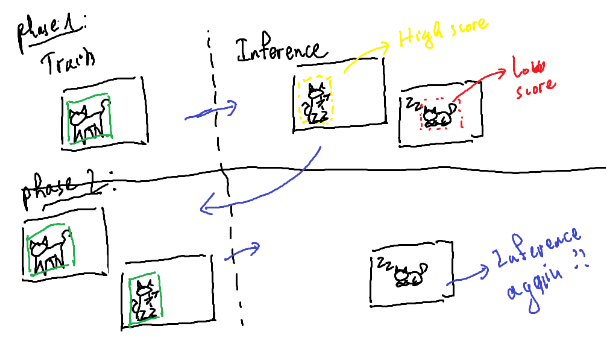
Fig. 12. Quá trình học pseudo labeling
Chúng ta đều biết nếu sử dụng cả source domain và target domain để huấn luyện (được gọi là oracle) thì kết quả chắc chắn sẽ tốt như mong muốn. Nhưng vấn đề ở đây là target domain không có annotations nên không thể sử dụng được. Phương pháp Pseudo-label based self-learning sẽ thực hiện training trên tập source domain, sau đó sẽ chạy dự đoán trên tập target domain, những samples kết quả dự đoán có confidence cao (không cần biết chúng có đúng hay không) sẽ lại được đưa vào source domain để thực hiện huấn luyện lại (hoặc tiếp tục) theo vòng lặp mới.
Hiện tại chưa có chứng minh cụ thể (hoặc mình chưa tìm ra) là tại sao phương pháp này có thể hoạt động được và nó tốt như thế nào, nhưng lớp phương pháp này đã giúp tăng performance ở hầu hết các thực nghiệm trên thực tế mà bạn có thể dễ thấy tại các cuộc thi như Kaggle, …
Fig. 13. Fail case của phương pháp Pseudo-label based self-learning
Kỹ thuật này khá thành công đối với classification và segmentation, nhưng đối với object detection, các bounding box đầu ra không phải lúc nào cũng đúng khi mô hình dễ dàng bị mơ hồ giữa foreground và background, chưa kể số lượng vật thể trong object detection là không cố định, khiến cho False Positive và False Negative đầu ra cho target domain chiếm một lượng lớn trong vấn đề domain shift.
Tất nhiên trong quá trình nghiên cứu kỹ thuật này đã được chỉnh sửa và phát triển để phù hợp với bài toán.
Kết luận
Vậy là chúng ta đã đi qua tổng quan về lớp bài toán thích ứng miền không giám sát cho các bài toán nhận diện đối tượng (Unsupervised Domain Adaptation for Object Detection) với 3 hướng phương pháp chính được nghiên cứu và sử dụng nhằm để thu hẹp domain distribution giữa các domains, nhằm học được tốt tính general của các đối tượng:
- Adversarial Feature Learning: Thực hiện domain shift tại các feature maps thông qua quá trình forward của mô hình.
- Image-to-image translation: Thực hiện domain shift ngay tại đầu vào mô hình, thông qua style transfer tạo ảnh source domain có tính style giống với target domain.
- Pseudo-label based self-learning: Thực hiện các vòng lặp huấn luyện mà trong đó, mỗi vòng lặp training trên source domain, thực hiện dự đoán trên target domain, lấy kết quả có confidence cao để đưa vào source domain để chuận bị thực hiện vòng lặp tiếp theo.
Ngoài ra, vẫn còn các lớp phương pháp khác như Domain randomization, Mean-teacher training, Graph reasoning,… nhưng các bài báo nghiên cứu khá ít, rải rác và hầu như chỉ sử dụng để góp phần hỗ trợ cho phương pháp chính là adversarial learning (theo kinh nghiệm cá nhân).
Tham khảo
Unsupervised Domain Adaptation of Object Detectors: A Survey
A theory of learning from different domains
Tổng hợp link paper và github cho mảng domain adaptation for object detection
Tìm hiểu thêm về Pixta Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Fanpage: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/