
1. Giới thiệu
1.1. Đặt vấn đề
Object Detection là bài toán cơ bản nhưng đóng vai trò lớn dùng để phân loại và xác định vị trí các đối tượng vật thể có trong ảnh hoặc video. Với sự phát triển vượt bậc về mặt dữ liệu cũng như nghiên cứu, bài toán Object Detection đã đạt được nhiều kết quả đáng ngưỡng mộ và được ứng dụng rất nhiều trong thực tế. Object Detection cho Super-resolution và Small Object Detection (SOD) là một mảng nhỏ được dùng để xác định các vật thể có kích thước tương đối nhỏ so với ảnh, một số ứng dụng quan trọng trong thực tế có thể kể đến là xác định vật thể thông qua ảnh vệ tinh, drone; nhận diện người, phương tiện giao thông qua các bài toán surveillance; nhận diện biển báo giao thông cho bài toán xe tự lái;…

Hình 1: Dự đoán vật thể cho bài toán Super-resolution và SOD
Khác với sự phát triển mạnh mẽ của các bài toán Object Detection thông thường, Super-resolution và SOD thường có ít nghiên cứu hơn và xu hướng phát triển chậm hơn. Theo thường thức, việc tăng kích thước ảnh lên sẽ khiến đặc trưng của các vật thể có thể được nhận biết rõ ràng hơn, từ đó kết quả dự đoán sẽ tốt hơn. Nhưng trên thực tế, đối với kết quả của các mô hình Object Detection thông thường, chúng ta sẽ thấy có một khoảng cách lớn về kết quả khi nhận biết đối tượng có kích thước nhỏ so với vật thể có kích thước vừa (Bảng 1).
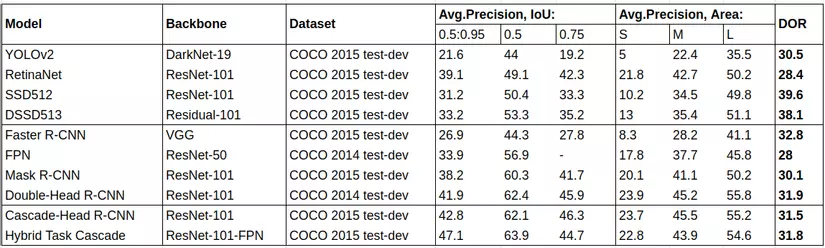
Bảng 1: Kết quả so sánh của các thuật toán Object detection thông thường trên tập MS COCO DATASET. Ở bên phải cùng là DOR (degrade of reduction), dùng để đo khoảng cách kết quả dự đoán cho vật thể lớn và vật thể nhỏ (càng nhỏ càng ổn định)
1.2. Khó khăn
Mất mát thông tin
Các vật thể có kích thước nhỏ thường có đặc trưng thấp và trong quá trình tích chập, việc giảm dần không gian để tạo ra các features map đại diện sẽ vô tình loại bỏ các vật thể đó cùng với môi trường, khiến cho mô hình không thể trích xuất được các đặc trưng đại diện cho vật thể đó.
Các đặc trưng đại diện trích xuất từ mô hình không ổn định
Các đặc trưng đại diện để phân biệt rất quan trọng cho việc phân loại và xác định vật thể. Các vật thể kích thước nhỏ thường có chất lượng kém và bị lẫn với môi trường xung quanh và vật thể khác, khiến các đặc trưng trích xuất sẽ chứa các nhiễu từ môi trường, ảnh hưởng đến kết quả nhận diện.
Với bài toán Super-resolution nói riêng, ảnh chất lượng cao đồng nghĩa với việc quá đa dạng kích thước cho vật thể, khiến cho môi trường tìm kiếm của bài toán tăng lên, mô hình sẽ cần thêm dữ liệu học được thêm cả đặc trưng kích thước của dữ liệu, chưa kể sự thiếu hụt dữ liệu có chất lượng cao liên quan, kết quả thường thấp hơn so khi áp dụng với những bộ dữ liệu phổ thông (COCO, ImageNet, …)
Kích thước vật thể ảnh hưởng khác nhau lên sự sai lệch của bounding box
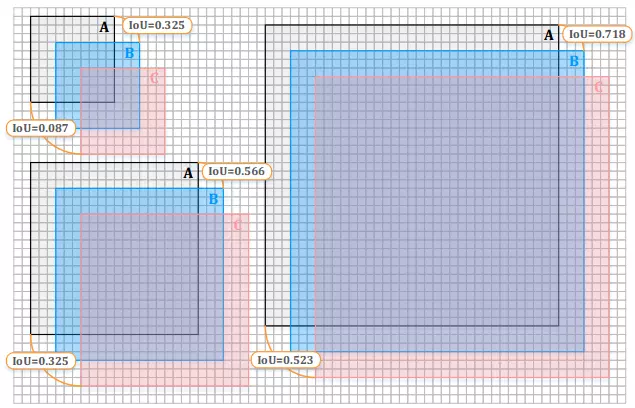
Hình 2: Kích thước vật thể ảnh hưởng lên sự sai lệch của bounding box. Trái trên, trái dưới, và phải tương ứng đại diện cho vật thể nhỏ (20×20), vật thể vừa (40×40) và vật thể lớn (70×70). A là Ground Truth (GT), B và C lần lượt là kết quả dự đoán nhưng lệch (trái phải 3 và 6 pixels tương ứng) so với GT.
Xác định tọa độ của vật thể là một trong những phần quan trọng trong bài toán Object Detection và kết quả này thường được đánh giá thông qua IoU (Intersection over Union) metric. Tuy nhiên kết quả đánh giá khi xác định tọa độ trên vật thể có kích thước nhỏ sẽ khó khăn hơn so với vật thể lớn hơn. Như trong hình ta thấy với việc để lệch 3 pixel theo chiều ngang và dọc so với Ground Truth, kết quả dự đoán của vật thể kích thước nhỏ giảm khá nhiều (từ 100% xuống 32.5%) so với vật thể có kích thước vừa và to (56.6% và 71.8%).
Kích thước vật thể so với toàn ảnh (hoặc video)
Nói về small object, thật sự không có quy định nào để xác định rõ ràng một vật thể được gọi là nhỏ hay không với một sample cụ thể. Với SOD, small object thường có kích thước khoảng 30×30, chiếm dưới <1% diện tích ảnh (256×256 – 512×512), thường vật thể sẽ khá mờ những vẫn có thể nhận biết được với mắt thường hoặc dựa trên môi trường xung quanh. Với Super-resolution, thường ảnh sẽ có kích thước khoảng 5000×5000 pixels (có thể lên tới 10000×10000 pixels hoặc hơn), nên gọi là vật thể có kích thước nhỏ nhưng có thể coi là kích thước vừa với những dữ liệu ảnh thông thường, khó khăn ở đây là khả năng tách đặc trưng của mô hình khi lượng tính toán cho dạng bài toán này là tường đối lớn. Nhưng với dữ liệu Super-resolution (5000×5000) nhưng vật thể có kích thước nhỏ tương đương với small object của dữ liệu thông thường (30×30), chiếm xấp xỉ 0.004% toàn ảnh, với sự bất lợi của cả 2 bài toán gộp lại, việc giải quyết vấn đề sẽ trở nên khó khăn hơn rất nhiều.
Thiếu hụt dữ liệu
Trong những năm gần đây, chúng ta thấy sự phát triển và đóng góp của nhiều bộ dữ liệu lớn và đa dạng, góp phần đánh giá và tạo nên sự phát triển mạnh mẽ cho các mô hình trong lĩnh vực Object Detection, những bộ dữ liệu quen thuộc có thể kể đến là COCO, Pascal VOC, ImageNet, … Nhưng đang tiếc, dữ liệu cung cấp cho các bài toán SOD và Super-resolution là không nhiều và không đa dạng về mục đích, chủ yếu đối tượng các bộ dữ liệu này nhắm đến là người đi đường, xe cộ, nhà cửa, … và thường là dữ liệu ở dạng vệ tinh.
Trong bài này, tôi sẽ giới thiệu tổng quan các nghiên cứu cũng như đánh giá từng nghiên cứu, phương pháp cho từng bài toán đã đề cập: SOD, Super-resolution và kết hợp của cả hai.
2. Các nghiên cứu cho đến hiện tại
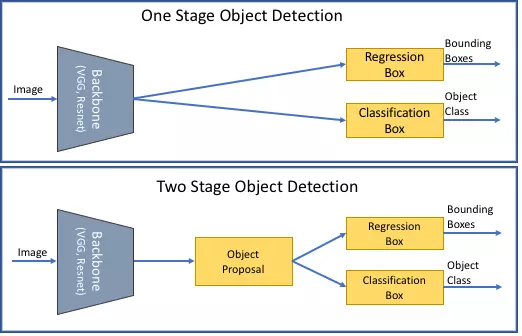
Hình 3: 2 lớp mô hình phổ biến cho bài toán Object detection. Trên: One-stage Object detection. Dưới: Two-stage Object detection
Các mô hình Object Detection hiện nay thường sẽ được xếp vào 2 loại: Two-stage detection và One-stage detection. Two-stage detection sẽ tạo ra các region proposals tốt thông qua lớp kiến trúc RPN (Region Proposal Network), sau đó detction head sẽ đưa vào các region proposals đó để phân vùng và xác định vật thể, một số mô hình phổ biến là họ R-CNN, FPN,… Khác với two-stage detection, one-stage detection sẽ trích xuất các đặc trưng theo grid-map với anchors box đã được xác định trước, từ đó phân vùng và xác định trực tiếp vật thể từ các đặc trưng đó, một số mô hình phổ biến như họ YOLO, SSD,… Việc lựa chọn một trong hai mô hình sẽ có sự trade-off khác nhau, khi one-stage detection sẽ ưu tiên hơn về tốc độ xử lý và two-stage detection sẽ cho ra kết quả chính xác hơn. Tất nhiên là ngoài 2 loại mô hình phổ biến thì còn có các loại mô hình Object Detection khác như họ Anchor-free (YoloX, CenterNet,…), Query-based (DETR),…
Thường từng đối tượng, mục đích mà bài toán Object Detection nhắm đến, nếu chỉ nói về việc sửa đổi mô hình thì các mô hình được sử dụng đều không khác biệt nhau quá nhiều, không nói đến vấn đề chỉ đơn giản là thay các loại backbone thì các mô hình cũng chỉ được sửa đổi các head và neck sao cho phù hợp với bài toán. Với các bài toán Super-resolution và SOD, các nghiên cứu nổi trội hiện tại thường thiết kế để thay đổi quy trình hoạt động, huấn luyện của mô hình sao cho vẫn chúng vẫn có thể hoạt động tốt với các mô hình Object Detection thông thường.
2.1. Data manipulation methods
Trên thực tế, việc một bộ dữ liệu được cân bằng về toàn bộ class cũng như kích thước là cực kì khó, các vật thể kích thước nhỏ thường chiếm số lượng khá ít so với mặt bằng chung (thường thấy ở các bộ dữ liệu phổ biến), nên thường mô hình sẽ nghiễm nhiên bỏ qua các vật thể đó khi kết quả (precision và recall) vẫn giữ được ở mức ổn định (vì số lượng vật thể nhỏ là ít).
Oversampling-based augmentation strategy


Hình 4: Một số phương pháp Oversampling augmentation. Trên: Copy-paste augmentation. Dưới: Mosaic augmentation
Sao chép các vật thể, scale và dán lên các vị trí phù hợp tại các sample khác nhau (copy-patse augmentation), tùy điều chỉnh mà dữ liệu đầu vào khi training sẽ trở nên cân bằng hơn. Phương pháp stitching (mosaic) ghép số lượng ảnh nhất định vào nhau (ví dụ: 4), giảm kích thước ảnh về kích thước ban đầu, tạo sample mới, giúp tăng số lượng vật thể có kích thước nhỏ bằng cách giảm kích thước của các vật thể ban đầu có trong ảnh (thông qua ghép và resize ảnh).
Các phương pháp đơn giản để cân bằng lại dữ liệu về mặt kích thước cũng như class, nhưng thường việc cắt ghép đơn giản này sẽ ảnh hưởng bởi sự mất tự nhiên của vật thể với môi trường mà nó được ghép vào. Với những vật thể nằm ở viền ảnh, khi ghép nối theo phương pháp stitching cũng gây mất tự nhiên, ảnh hưởng tới kết quả. Vì vậy loại phương pháp này đạt kết quả tốt hay không sẽ tùy thuộc khá nhiều vào dữ liệu.
Automatic augmentation scheme
Ngoài việc tùy chỉnh điều kiện để tạo ra các phương pháp augmentation phù hợp theo quy tắc phù hợp, chúng ta có các thuật toán để tự động tìm kiếm các điều kiện đó sao cho kết quả của phương pháp augmentation đạt được là tối ưu nhất. Do đó, phần nhiều phương pháp automatic augmentation hiện tại là bài toán tối ưu tham số và Reinforcement learning là phương pháp tự động tìm kiếm khá hiệu quả (AutoAugment), nhưng yêu cầu lượng tính toán khổng lồ do không gian tìm kiếm thường rất lớn (so với kích thước của ảnh, số lượng sample và lượng class tương ứng).
2.2. Scale-aware methods
Vật thể trong ảnh thường đa dạng về kích thước và tỉ lệ chiều rộng chiều dài, nhất là đối với ảnh Super-resolution, sự khác biệt đó càng lớn hơn, khiến cho mô hình đơn (single detector) dự đoán khá khó khăn. Thường đối với một mô hình, từ các nghiên cứu thực nghiệm, việc dự đoán các vật thể với dải kích thước cố định (hoặc có độ dao động thấp) sẽ dễ dàng hơn nhiều so với dữ liệu có dải kích thước có độ dao động cao (đa dạng về kích thước), nên các phương pháp hiện tại sẽ xử lý ảnh (hoặc trong quá trình trích xuất đặc trưng), với với đầu vào cụ thể thì mô hình (hoặc một phần mô hình) chỉ cần dự đoán vật thể trong dải kích thước cố định, có thể bỏ qua các vật thể quá lớn hoặc quá nhỏ, những trường hợp này sẽ được xử lý với đầu vào khác (cùng sample).
Multi-scale detection
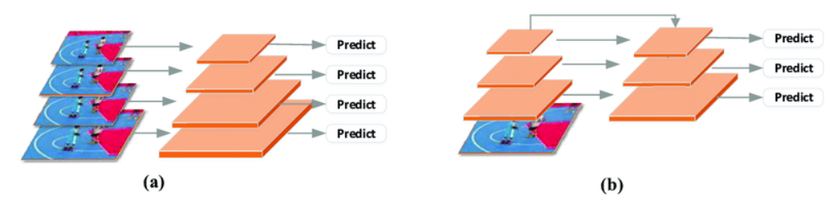
Hình 5: hai loại phương pháp multi-scale detection. a, image pyramid methods. b, features pyramid methods
Giải pháp có thể nghĩ đến là chia một ảnh thành nhiều scale khác nhau (image-pyramid) để dự đoán từng scale một (TridentNet, PANet, QueryDet, …) hoặc sẽ dự đoán trên features map đầu ra của từng layers (feature-pyramid) (HyperNet, SSD, YOLO, …).
Vì phải dự đoán nhiều lần (dựa trên nhiều scales hoặc features map) nên phương pháp này cần lượng tính toán lớn (nhất là với ảnh super-resolution).
Tailored training schemes

Hình 6: Quy trình dự đoán của lớp thuật toán Tailored training schemes. Với mỗi chu kỳ, từ một sample ảnh cụ thể, thuật toán sẽ đồng thời nhận diện vật thể và tìm kiếm vùng có khả năng chứa vật thể nhỏ hơn, từ các vùng thích hợp đó sẽ hình thành sample ảnh mới, tiếp tục cho chu kỳ tiếp theo. Đến khi không còn tìm kiếm ra vùng thích hợp nào nữa thì thuật toán sẽ gộp hết kết quả dự đoán lại, đưa ra kết quả cuối cùng.
Trong một ảnh, số lượng pixels của background là cực kỳ lớn, nên việc cố gắng tách đặc trưng tại các vùng không gian không chưa vật thể có vẻ rất thừa thãi, dựa trên ý tưởng đó, các phương pháp liên quan thường sẽ hoạt động như sau: sample ảnh và scale về kích thước cố định –> nhận diện vật thể và vùng có khả năng chưa vật thể –> tách vùng có khả năng chứa vật thể, tạo nên sample mới. Và cứ thế lặp lại quy trình đến khi không còn nhận diện được nữa thì dừng lại.
Điểm lợi của lớp phương pháp này là với mỗi đầu vào, ảnh sample sẽ được resize lại về kích thước đủ nhỏ để tính toán (vì có thể bỏ qua các vật thể nhỏ cho chu kỳ tiếp theo xử lý), nhất là với ảnh super-resolution, khi kích thước đầu vào ban đầu là quá lớn.
Các phương pháp thuộc họ SNIP (Scale Normalization for Image Pyramids) ứng dụng quy trình này để đồng thời dự đoán vật thể và dự đoán ra các chips (sample ảnh nhỏ hơn từ ảnh sample ban đầu) để tiếp tục sử dụng cho chu kỳ tiếp theo.
Việc dự đoán vùng có khả năng chứa vật thể theo phương pháp trên khá trừu tượng vì bài toán dự đoán chips của họ phương pháp này có phương pháp training gần giống với bài toán segmentation (mong muốn đầu ra của features map sẽ bao đủ vật thể tương ứng). Các bài toán tự động tìm ra vùng chứa vật thể bằng Reinforcement learning cũng đã được nghiên cứu và sử dụng. Với sample ảnh hiện tại, thuật toán sẽ đi tìm vùng ảnh khả năng cao là có vật thể, dựa trên số lượng (hoặc tổng diện tích) vật thể có và lượng dư thừa của background, thuật toán sẽ tính toán và trả về reward dể cập nhật mô hình. Tuy nhiên, thời gian học, tính toán và tối ưu của một mô hình Reinforcement learning phụ thuộc nhiều vào không gian tìm kiếm (không gian tìm kiếm càng lớn thì tốc độ tối ưu càng lâu), và lượng tổn thất này thường rất lớn so với giá trị nó có thể đem lại trên thực tế.
2.3. Feature-fusion methods
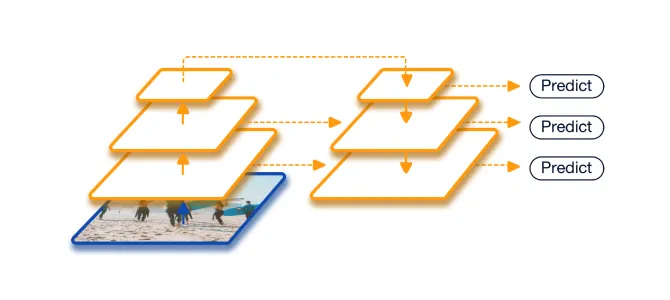
Hình 7: Tổng quan ý tưởng mô hình cho lớp thuật toán Feature-fussion
Các mô hình kiến trúc Deep CNN thường tạo ra các features map nối tiếp nhau với kích thước khác nhau, các đặc trưng tạo ra từ các layers nông sẽ có nhiều thông tin về mặt không gian hơn và các đặc trưng tạo ra từ các layers sâu sẽ hình thành được nhiều đặc trưng thông tin sâu hơn của từng vùng, do vấn đề vật thể nhỏ có thể sẽ biến mất trong quá trình trích chọn đặc trưng ở các layers sâu, lớp phương pháp Feature-fusion sẽ kết hợp đặc trưng của các đầu ra lại với nhau theo một quy tắc nào đó, vừa có đặc trưng sâu của vùng vật thể, vừa giữ được thông tin không gian của vật thể, tạo ra đặc trưng đại diện ổn định hơn.
Những mô hình thuộc phương pháp này phổ biến mà bạn có thể thấy gần đây là FPN, PANet, DarkNet, SSPNet, … đều kết hợp features tạo ra từ layers nông với features tạo ra từ layers sâu hơn (có thể kết hợp đơn giản bằng việc up-sampling và hợp hoặc cộng với nhau, hoặc refined kích thước của features nông thông qua lớp refined network cơ bản).
Nhưng kết quả của lớp phương pháp này sẽ tùy thuộc nhiều vào vấn đề mà chúng gặp phải. Với bài toán SOD, vật thể quá nhỏ sẽ thường gán với lớp đặc trưng nông nhất, tương tự sẽ ghép với đặc trưng ngữ nghĩa sâu nhất, khi sample qua các layer càng sâu thì các vật thể nhỏ sẽ dần biến mất đi đặc trưng của nó, dẫn tới vấn đề đặc trưng nông thì cực kì ít thông tin ngữ nghĩa và đặc trưng sâu lại làm mất đi thông tin của vật thể, khiến cho lượng tính toán không những bị thừa thãi mà còn không tạo ra được giá trị cao. Với bài toán Super-resolution, khi kích thước vật thể là cực kỳ đa dạng, có thể cùng tồn tại vật thể có kích thước (30×30) và vật thể có kích thước (1000×1000), việc tạo ra vài features map đại diện có thể sẽ không đủ và phải tăng thêm các lớp layers nông và sâu để kết hợp với nhau, tuy nhiên sẽ rất tốn tài nguyên để tính toán vì vốn dĩ việc chạy mô hình cho một ảnh Super-resolution là rất khó khăn rồi.
2.4. Super-resolution methods

Hình 8: Phục hồi ảnh sử dụng lớp mô hình GAN cho preprocessing trước khi đưa vào mô hình Object detection
Để tránh sự mất mát đặc trưng của vật thể nhỏ do kích thước của chúng trong quá trình trích chọn đặc trưng của mô hình, một hướng tiếp cận đơn giản có thể nghĩ đến là tăng chất lượng ảnh lên cao hơn. Ví dụ khi tăng chất lượng ảnh lên gấp 10 lần đồng nghĩa với việc tăng kích thước ảnh lên 10 lần, khi đó chúng ta sẽ quay trở lại bài toán Super-resolution với vật thể ở kích thước vừa (và phương pháp này chỉ nên áp dụng cho bài toán SOD với ảnh có kích thước thông tường (256, 512,…) vì bài toán Super-resolution vốn dĩ ảnh đã rất lớn rồi), và hi vọng việc tăng kích thước của vật thể sẽ khôi phục sự méo mó, trừu tượng của vật thể đó, khiến chúng trở nên rõ ràng hơn.
Việc gia tăng kích thước thường có 2 hướng: Learning-based và GAN-based. Learning-based là tăng kích thước của các features map trong quá trình huấn luyện, cách hoạt động của chúng gần tương tự với Feature-fusion methods nên tôi sẽ không đề cập tới nữa. GAN-based, như tên gọi, sẽ sử dụng các thuật toán GAN để tăng kích thước cho ảnh, hay nói cách khác là phục hồi ảnh, nhằm khôi phục sự rõ ràng của vật thể, giúp đặc trưng trích xuất sẽ mang nhiều ngữ nghĩa về vật thể hơn.

Hình 9: Mô hình GAN dùng để phục hồi ảnh tạo ra khá nhiều nhiễu và artifact, có khả năng làm hỏng cả thông tin của vật thể
Như đã đề cập, việc tăng chất lượng ảnh sẽ đưa bài toán SOD về bài toán Super-resolution với vật thể ở kích thước trung bình, như vậy ta sẽ cần tới 2 mô hình để giải quyết bài toán so với các lớp phương pháp trước, điều này sẽ dẫn tới trade-off giữa lượng tài nguyên tính toán và kết quả tổng thể. Hơn nữa, với các mô hình GAN, ngoài việc training rất phức tạp thì có thể sẽ sinh ra các vật thể lạ (artifacts) hoặc ngữ cảnh hơi khác so với ban đâu, có thể ảnh hưởng tới chất lượng đầu ra.
2.5. Context modeling methods
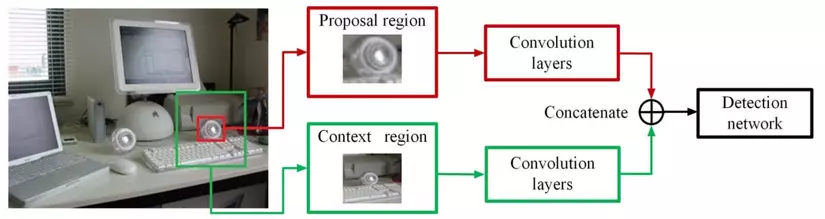
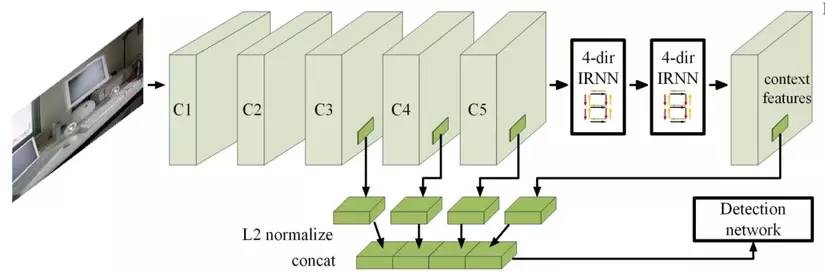
Hình 10: Một số mô hình đại diện cho lớp bài toán context modeling, tìm kiếm vùng đặc trưng cho vật thể cũng như ngữ cảnh xung quanh của vật thể đó, sau đó kết hợp lại để dự đoán ra kết quả cuối cùng
Các vật thể nhỏ thường chiếm một lượng rất nhỏ trong ảnh và bị lẫn với môi trường với các đối tượng vật thể khác. Với các mô hình Object Detection thông thường, thuật toán thường tập trung vào bản thân của vật thể để tạo ra các đặc trưng đại diện và có thể bỏ qua thông tin ngữ cảnh xung quanh. Chính vì các vật thể luôn luôn lẫn với môi trường nên chúng ta có thể tận dụng các thông tin môi trường đó để hỗ trợ nhận diện vật thể đó, đó chính là ý tưởng cho lớp bài toán context modeling, ngoài việc trích xuất vùng proposal của vật thể thì thuật toán cũng sử dụng đặc trưng của các vùng ngữ cảnh xung quanh để hỗ trợ nhận diện vật thể.
Cũng như các lớp phương pháp trước, lớp phương pháp có thể sử dụng trên toàn ảnh hoặc thông qua các features map tại các layers. Dưới đây là 2 ví dụ cho từng phương pháp.
ContextNet thông qua mô hình sẽ trích xuất đồng thời đặc trưng của proposal region cũng như context region xung quanh nó (hình 10, trên), 2 vung này sẽ đi qua một lớp tích chập, trích đặc trưng và kết hợp với nhau, từ đó nhận diện và xác định vật thể đó.
Inside-Outside Net sẽ tìm kiếm các vùng thông tin ở các features map khác nhau, kết hợp các đặc trưng thông tin đó, sử dụng mô hình RNN để từ các đặc trưng kết hợp đó, tạo ra đặc trưng ngữ nghĩa cuối cùng cho vật thể, từ đó sử dụng để nhận diện và xác định vật thể (hình 10, dưới).
3. Kết luận
Bài viết trên đã trình bày tổng quan về SOD và Super-resolution cũng như các nghiên cứu về dữ liệu, bài toán và mô hình liên quan. Các lớp thuật toán là đa dạng nhưng không có dạng nào là triệt để cả, mỗi hướng đi đều có điểm mạnh và điểm yếu riêng và phụ thuộc nhiều vào bài toán mà chúng ta muốn hướng tới. Ưu điểm chung duy nhất nhưng đóng vái trò quan trọng là tất cả hướng đi đều phát triển nhưng không tác động quá nhiều vào mô hình (thậm chí là giữ nguyên), điều này giúp ta có thể kế thừa kiến thức cho mô hình từ các bộ dữ liệu lớn. Cũng chính vì không tác động quá nhiều vào mô hình và tập trung chủ yếu vào việc xử lý quá trình huấn luyện, dự đoán để phù hợp với bài toán domain, các lớp thuật toán này hoàn toàn có thể kết hợp với nhau để tận dụng các lợi thế nó mang lại nhưng cần phải xem xét cẩn thận vấn đề mà bài toán bản thân muốn hướng đến để chọn các lớp thuật toán sao cho phù hợp.
Tham khảo
– Towards Large-Scale Small Object Detection: Survey and Benchmarks (https://arxiv.org/abs/2207.14096)
– A Survey of the Four Pillars for Small Object Detection: Multiscale Representation, Contextual Information, Super-Resolution, and Region Proposal (https://ieeexplore.ieee.org/document/9143165)
– Super-resolution and Object Detection: A love story (https://medium.com/the-downlinq/super-resolution-and-object-detection-a-love-story-part-1a-2f1e962e99dd)
Tác giả: Đỗ Quang Mạnh
Tìm hiểu thêm về cơ hội làm việc tại Pixta Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Facebook: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/
✉️ Email: recruit.vn@pixta.co.jp
☎️ Hotline: 024.6664.1988