Part 2: System-Level and Deployment-Centric Optimization for LLMs
In Part 1, we looked at the internal mechanics of big language models, concentrating on architectural strategies such as sparse attention, cache compression, and speculative decoding to reduce compute and memory costs during inference.
However, even the most intelligent model optimizations can fail if the underlying system is not scale-ready.
In this part, we go beyond model internals to look at infrastructure-aware solutions including scheduling and weight management. These methods are critical for installing LLMs in production environments, particularly when dealing with multi-GPU servers, edge devices, or limited cloud budgets.
Whether you’re an ML engineer, infrastructure architect, or researcher, understanding these system-level strategies can help you install scalable and cost-effective LLMs.
Theme 4: Weight Scheduling
Scheduling is about balancing a model weight across a physical machine’s resources, including GPU, CPU, and hard disk. This strategy not only allows speeding up inference by computing in parallel, but also provides a chance for big models like 100B parameter models to be executed on a low-resource PC with a T4 GPU.
The general solution to realize the action lies in two key factors:
- Load / off-load a model’s weight smartly across the GPU, CPU, and hard disk.
- Handle I/O data transfer well among the computation units.
Flexgen
Flexgen, proposed by a group of authors from Stanford, UC Berkeley, and CMU, is one of the most interesting papers that presents the idea for resolving two key factors.
The inference process is commonly described in the figure below. Each block of data needing handling is defined as a batch of data loaded onto a model layer. The column is batch-wise, while the row is layer-wise.
We define a valid path as a path that traverses (i.e., computes) all squares, while subject to the following constraints:
- Execute from left to right
- All data must be on the same device
- Activation needs its right sibling (square done)
- KV cache is stored until the most right data is done
- At any time, the total size of tensors stored on a device cannot exceed its memory capacity.
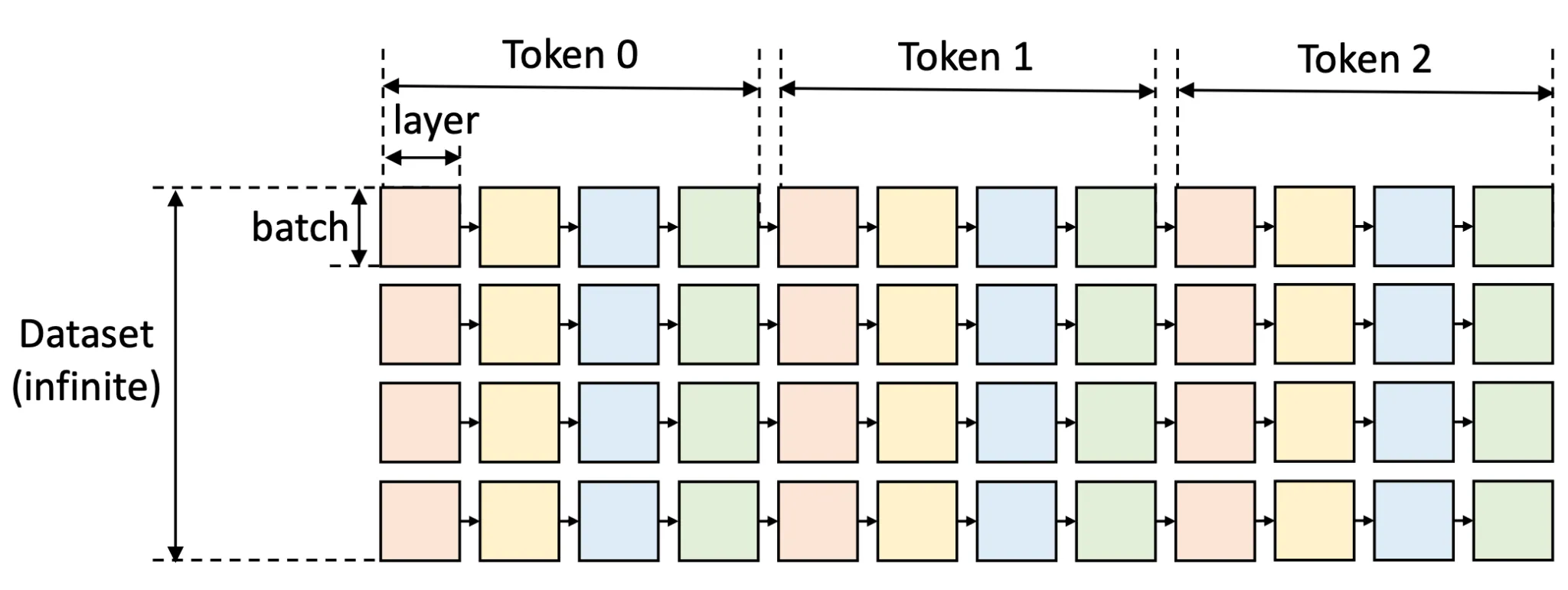
If we have n tokens, each token’s data will be loaded and computed in order of the tokens. Each layer weight will be loaded when needed to calculate the data, but offloaded after the computation. Continuous loading and offloading cost a lot of time since GPU computation speed is like a flash, while memory transferring speed is like a snail.
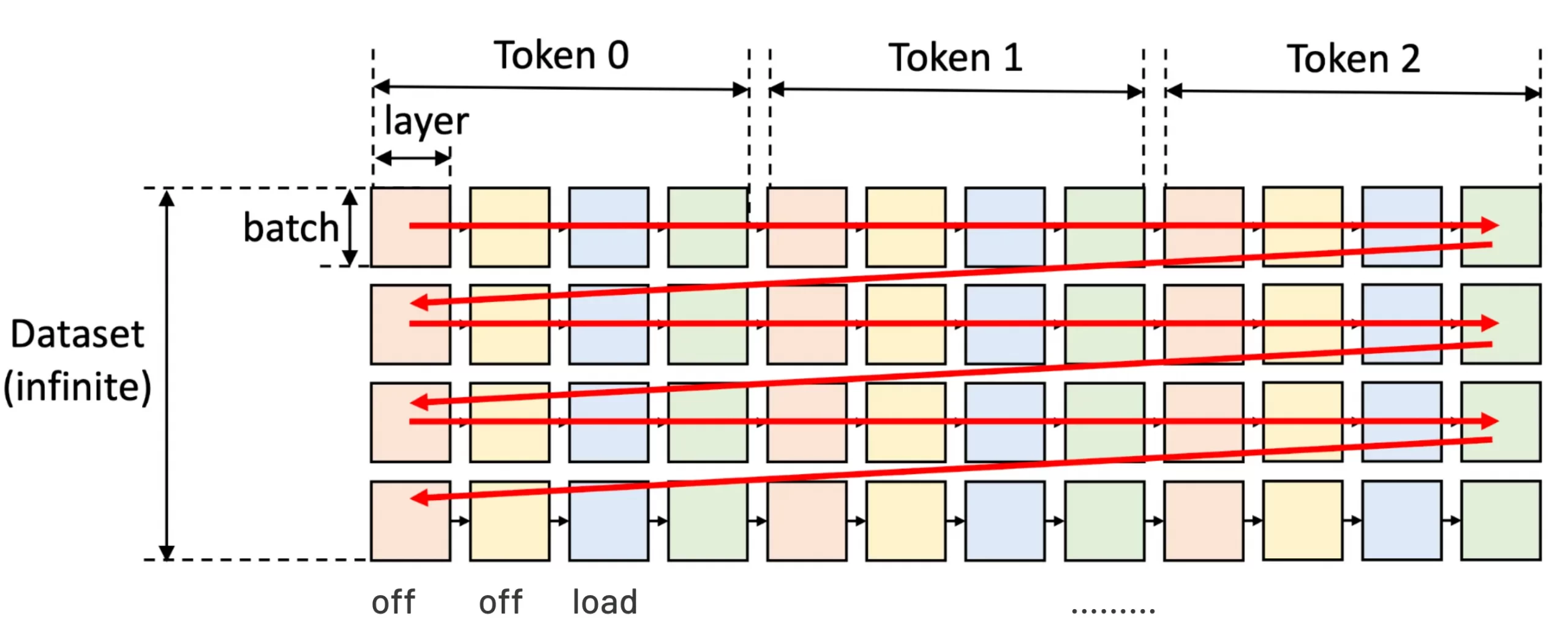
In the figure, a square means the computation of a GPU batch for a layer. The squares with the same color share the same layer weights
Flexgen optimised this process by adjusting from row to column scanning or a zig-zag block schedule. It saves layers’ weight without I/O and saves activation for the next column. During block execution, FlexGen overlaps: loading the weights of the next layer, storing activations/KV cache of the previous batch, and then computing the current batch. This strategy handles the memory transfer problem well.
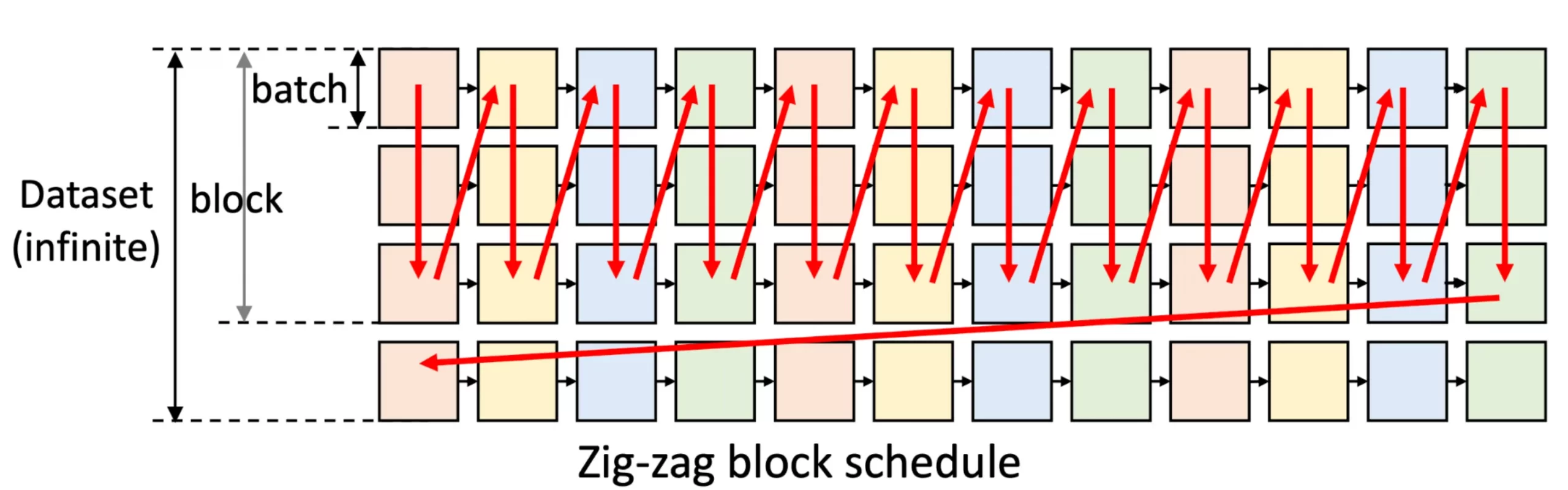
The next thing we must consider from FlexGen is how to put the model weights across all the hardware.
Flexgen uses Linear Programming Policy Search to find the optimal load configuration that satisfies the objective: minimum time to infer the whole model.
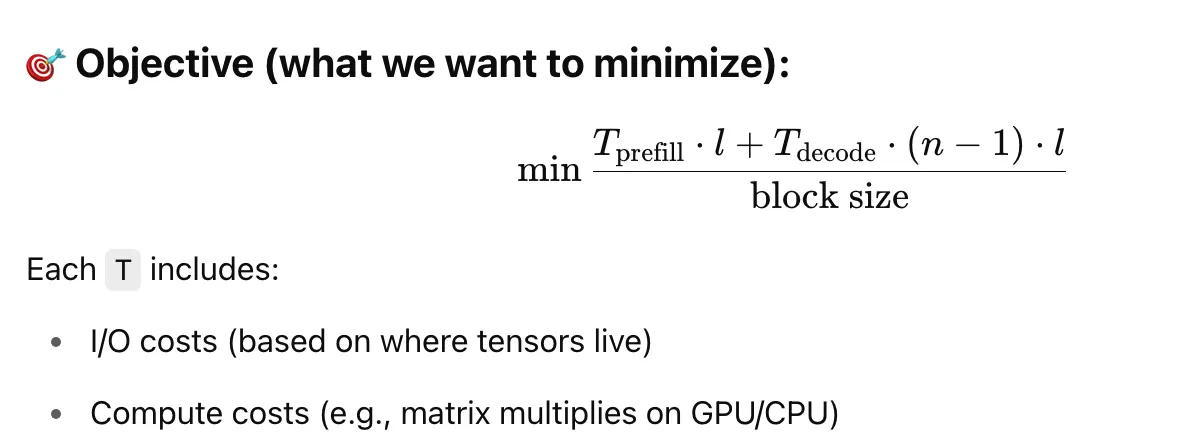
While
- n: number of output tokens per sequence
- 𝑙: number of transformer layers
- block size: how many examples you process in a block (batch size × num batches)
See the example below of how FlexGen configure a model OPT-30 B to run on a T4 machine.


The following is the paper’s statement when compared to the DeepSpeed and the Accelerate library of HuggingFace. It’s claimed to run up to 7.32 tokens per second, while this number in DeepSpeed is 1.57 tokens per second and 0.62 tokens per second in Accelerate.

Theme 5: System-Level Optimisation
Existing LLM serving systems (e.g., vLLM, Orca) often use a a First-Come-First-Serve (FCFS) mechanism and run-to-completion execution, which causes head-of-line (HOL) blocking — simply understanding: long jobs delay short ones. This leads to high queuing delays, up to 90% of total latency in real workloads. Look at the statistics below, which were observed in the paper FastServe.
*Note: When we mention short and long requests, it is not about the length of the prompt but about the time to generate the answer, the first token.
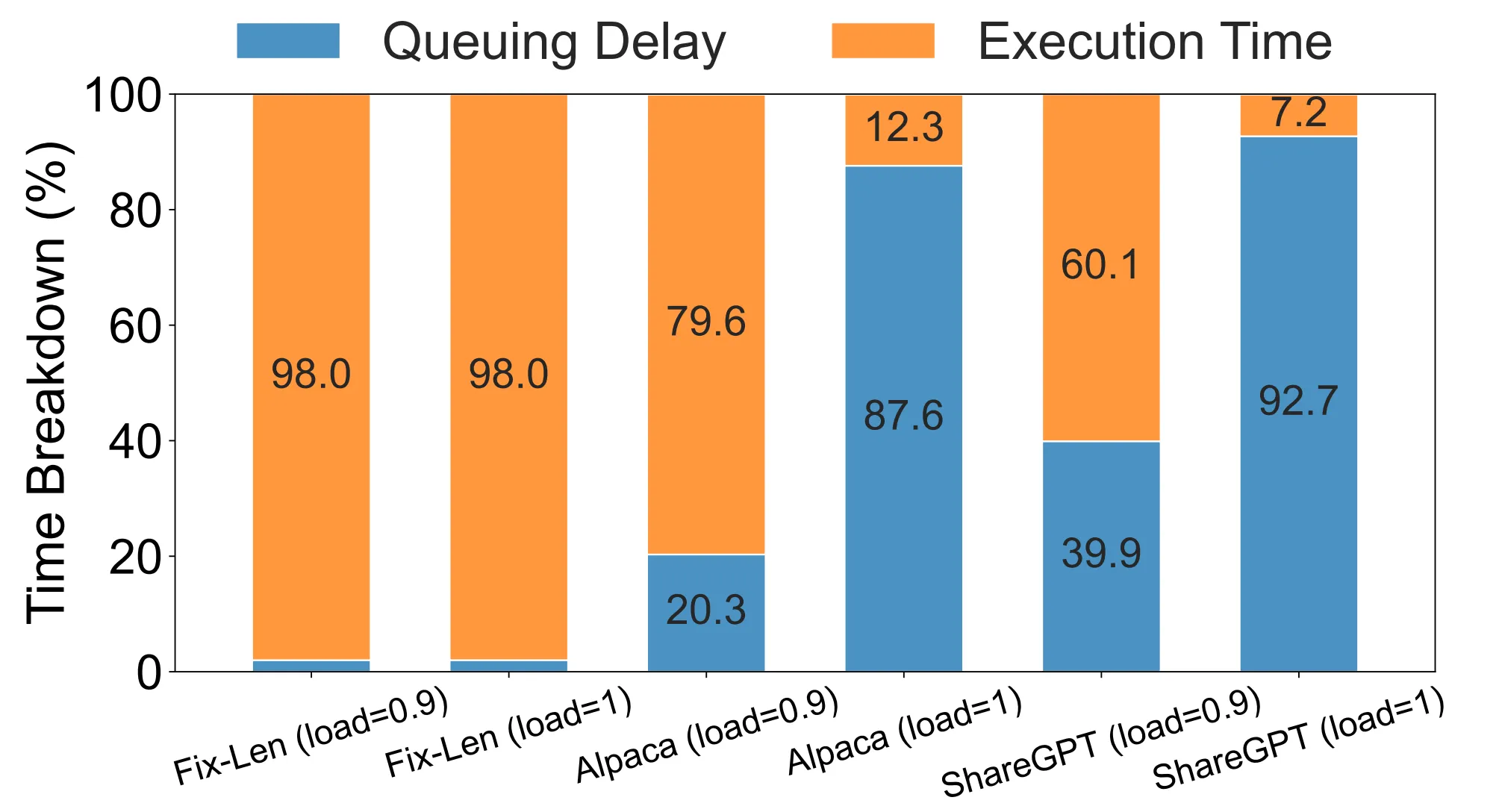
time by execuation vs queuing. Image source
The answer to this problem is to enable long requests to be interrupted, put the completed part in a cache, preserve the undone part for later processing, and then switch to the shorter request. Once the shorter request is completed, we return to run the remainder of the longer one. The solution requires a multi-queue implementation with different priorities.
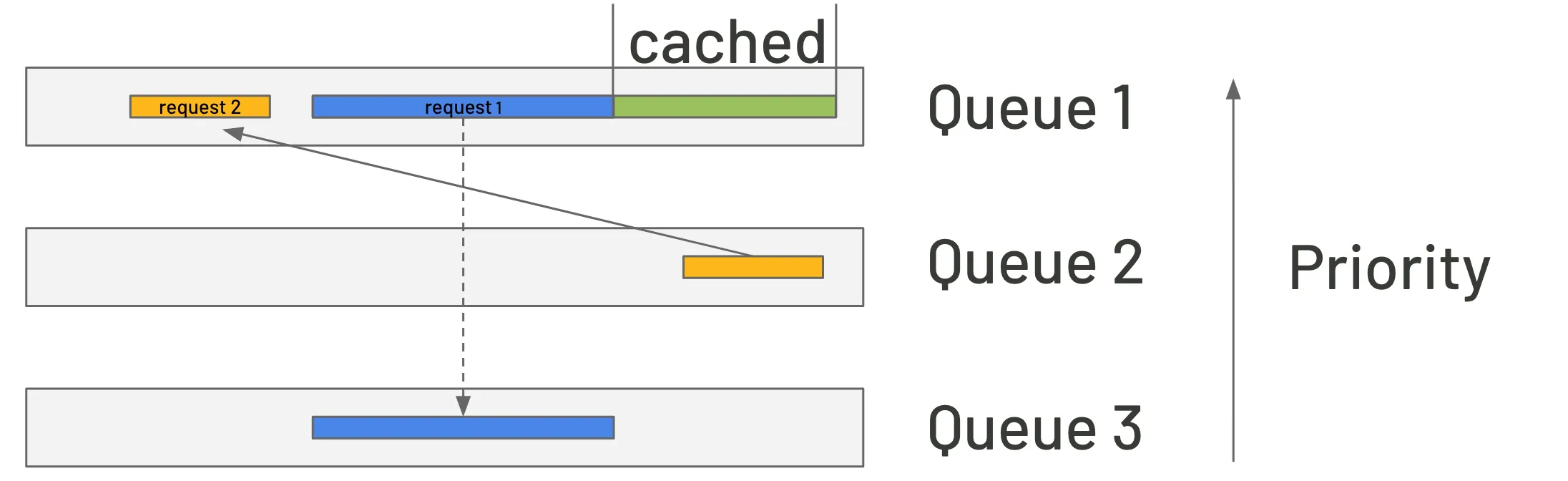
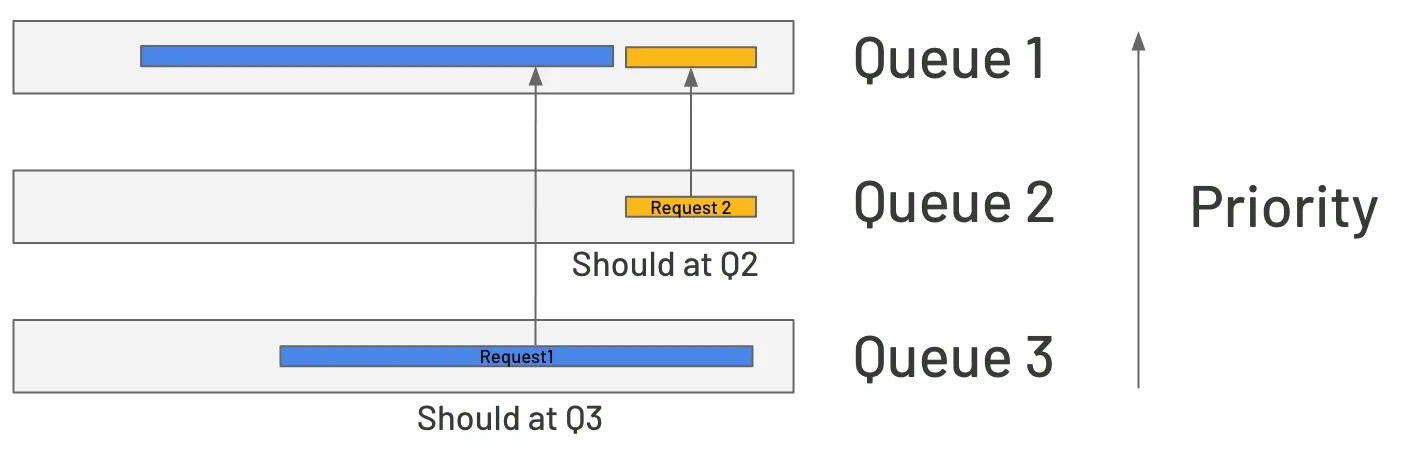
Still a problem with this idea: if there are many long requests in the higher-level queues before the short request, it may give the vision that the long requests were interrupted numerous times before switching to the small one. This not only increases the time it takes to handle a long one, but it also causes extra strain on the cache.
FastServe addresses the issue by adding the Skip-Join MLFQ (Multilevel Feedback Queue). When the system receives a request, it estimates the time required to generate the first token. By then, the request has been routed to the appropriate priority queue without interfering with shorter requests. Furthermore, KV cache management allows for proactive data movement between queues before the GPU processes the previous ones, reducing latency.
Other themes:
Many other themes optimize LLM inference, which I would want to omit in this essay because they are so common and used by many engineers every day. I just list the theme and the reference papers below:
Quantization
Reduces the precision of weights and activations (e.g., from FP16 to INT4 or FP8) to shrink model size and increase inference speed with minimal quality loss.
- AWQ
Activation-aware quantization using activation-driven importance scoring. Enables low-bit inference (e.g., INT3) without retraining. - LLM.int8()
Introduces post-training INT8 matrix multiplication with calibration. Supports transformer inference without accuracy degradation. - SmoothQuant
Aligns activation and weight ranges across layers for better post-training quantization performance. - ZeroQuant / V2 / FP
Low-bit quantization techniques (INT4, FP4) using calibration and low-rank compensation. - LLM-FP4
Demonstrates that FP4 representation can maintain model quality while significantly improving inference speed.
Early Exit Inference
- LITE
Intermediate layers learn to make predictions. Tokens exit early when confidence is high, saving up to 38% FLOPS.
Attention Optimization
- FlashAttention 1, 2, 3
Fast, exact attention using memory tiling. Outperforms standard implementations in speed and memory. - ROFormer
Introduces rotary position embedding to improve long-range generalisation. - StreamLLM
Allows attention to adapt dynamically to new input chunks during streaming
Non-autoregressive LLMs
- Diffusion-LM: Improving Controllable Text Generation: a first major work applying diffusion to text generation.
And more (I will update later)
Tool: How to use such techniques
vLLM is an open-source library that makes large language model (LLM) inference (running models) much faster and more efficient.
Researchers at UC Berkeley developed it and focus on high-throughput, low-latency serving of LLMS. The library started with the idea of PageAttention, but has now implemented nearly all the techniques I mentioned above. vLLM holds one of the biggest communities in LLM Inference Optimization I have seen.
We’ve seen how system-level optimization techniques, such as weight paging in FlexGen and request scheduling strategies, can boost the efficiency of big language models much beyond what algorithmic adjustments alone can provide.
By integrating these strategies with architectural advances from Part 1, engineers and researchers may create LLM-serving stacks that are not only faster and less expensive, but also scalable to real-world workloads. Whether you’re deploying on a single GPU or scaling across data centers, knowing these concepts is essential for unlocking the next generation of high-performance AI.
The full article is published at: https://medium.com/gopenai/the-art-of-llm-inference-fast-fit-and-free-c9faf1190d78
To read more about my last article and future articles, follow me at: https://trungtranthanh.medium.com