
Trong quá trình triển khai các mô hình AI trên nền tảng AWS, mình nhận thấy có một vấn đề lớn: các máy sử dụng GPU thường có chi phí khá cao nhưng hiệu quả mang lại chưa thật sự tương xứng, tình trạng bị lấy lại Spot Instance bất ngờ khiến việc duy trì hạ tầng AI trở nên khó lường. Vì vậy, mình mới bắt đầu tìm hiểu các lựa chọn thay thế, một trong số đó là dòng instance có chip được thiết kế dành riêng cho việc suy luận (inference) mô hình AI mà không dùng GPU truyền thống – cụ thể là AWS Inferentia 2. Sau một thời gian thử nghiệm, kết quả đạt được khá tích cực và phần nào đáp ứng được kỳ vọng ban đầu.
Giới thiệu về AWS Inferentia 2
AWS Inferentia 2 là loại chip đời thứ 2 được thiết kế bởi Amazon nhằm mang lại hiệu suất cao với mức giá thấp nhất trên Amazon EC2 cho các ứng dụng Deep Learning và Generative AI. Với khả năng suy luận mô hình có thông lượng cao (high-throughput) và độ trễ thấp (low-latency), nó là giải pháp lý tưởng để triển khai các mô hình trên môi trường production, đặc biệt là trong lĩnh vực như xử lý ngôn ngữ tự nhiên (NLP), thị giác máy tính (CV), AI tạo sinh (generative AI). Điều này khiến nó trở thành một giải pháp thay thế hấp dẫn cho inference thay vì GPU truyền thống.
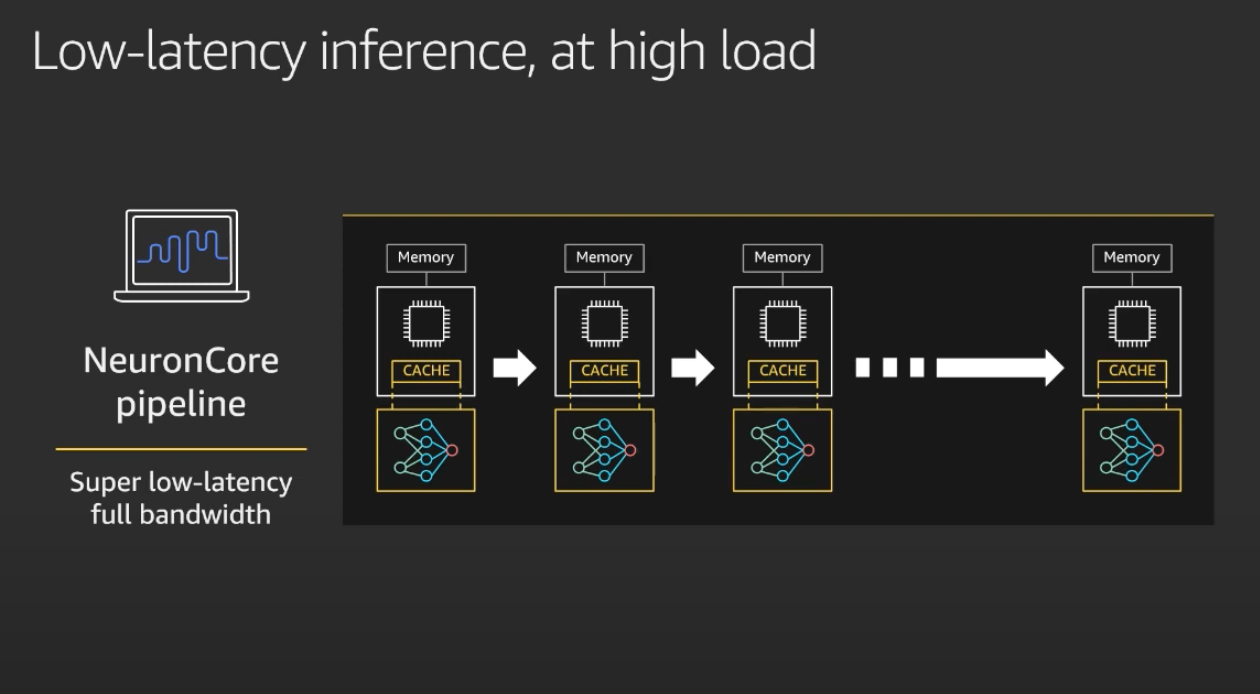
AWS Inferentia cho phép chia sẻ mô hình trên nhiều chip nhằm tăng tốc độ inference
Cách cài đặt
Để chạy những model trên máy Inf2, AWS cung cấp Neuron SDK, công cụ này bao gồm: Neuron Compiler (neuronx-cc): hỗ trợ việc chuyển đổi/biên dịch model thành dạng nhị phân được tối ưu Neuron Runtime: thực thi các mô hình đã được biên dịch Neuron Framework Extensions: chứa những thư viện mở rộng hỗ trợ cho các model TensorFlow, PyTorch và HuggingFace khi chạy trên chip Inferentia
Luồng thực hiện:
1. Chuyển đổi/biên dịch: model được theo dõi (traced) và biên dịch dùng trình biên dịch NeuronX.
Dưới đây là ví dụ cách biên dịch một model PyTorch sang định dạng Neuron:

2. Thực thi model: Sau khi model được biên dịch, thực hiện chạy model.
3. Inference: Model được chạy sử dụng Neuron runtime thông qua một framework tương ứng (PyTorch, HuggingFace).

Thử thách khi sử dụng
1. Giới hạn sự hỗ trợ tuỳ theo loại model
Hiện tại, không phải toàn bộ các loại model đều được hỗ trợ. Ví dụ:
- Các kiến trúc động phức tạp liên quan đến các phép toán tensor có thể không dễ biên dịch.
- Một số model Transformer của HuggingFace (vision-language, multimodal model) có thể bị compile sai.
2. Yêu cầu hình dạng đầu vào cố định
Các model sau khi được biên dịch thường yêu cầu dạng đầu vào cố định:
- Thời điểm biên dịch: tạo ra model dạng nhị phân được tối ưu.
- Thời điểm chạy: tránh lỗi lệnh định dạng.
Hiện nay, phần cứng đã được hỗ trợ cho định dạng đầu vào động (dynamic input shapes), nhưng Neuron SDK vẫn chưa hỗ trợ.
Các cách giải quyết được đưa ra: Padding và Bucketing
- Padding: Những đầu vào sẽ được padded thành một dạng cố định (image width/height, độ dài token).
- Bucketing: Biên dịch model thành nhiều model với nhiều dạng đầu vào khác nhau (128, 224, 664, …), sau đó thêm logic chọn model theo đầu vào lúc chạy.
Những cách tiếp cận này cải thiện vấn đề khả năng tương thích của model với chi phí bộ nhớ và độ phức tạp tăng thêm.
Sử dụng model EVA-02 CLIP cho Zeroshot image classification
Tôi đã thử chạy với model EVA-02 CLIP để giải quyết bài toán bài toán Image classification với bộ dataset 3000 ảnh. Sau khi biên dịch model dùng Neuron SDK và deploy trên Inf2.xlarge. Kết quả được so sánh với phương pháp dùng GPU truyền thống (Original – g4dn.xlarge).
Những chỉ số đánh giá:
- Về tốc độ giữa Inf và Original
- Tốc độ của Inf2 cực kì nhanh, median chỉ bằng ~0.05 giây, ổn định và hầu như không có outlier.
- Trong khi, GPU có median ~0.35 giây, biến động lớn và trải dài tới hơn 1 giây.
- Median inference của Inf2 nhanh hơn khoảng 7 lần so với GPU.

- Về độ chính xác
- Độ đồng thuận lên đến 99.87%, chỉ có 4 ảnh cho ra các kết quả khác nhau (2 ảnh model Original đoán đúng và 2 ảnh model Inf đoán đúng).
Kết luận
AWS Inferentia2 (inf2) cung cấp một phương pháp thay thế mạnh mẽ và tối ưu về giá cả so với GPU truyền thống cho việc inference trên môi trường production.
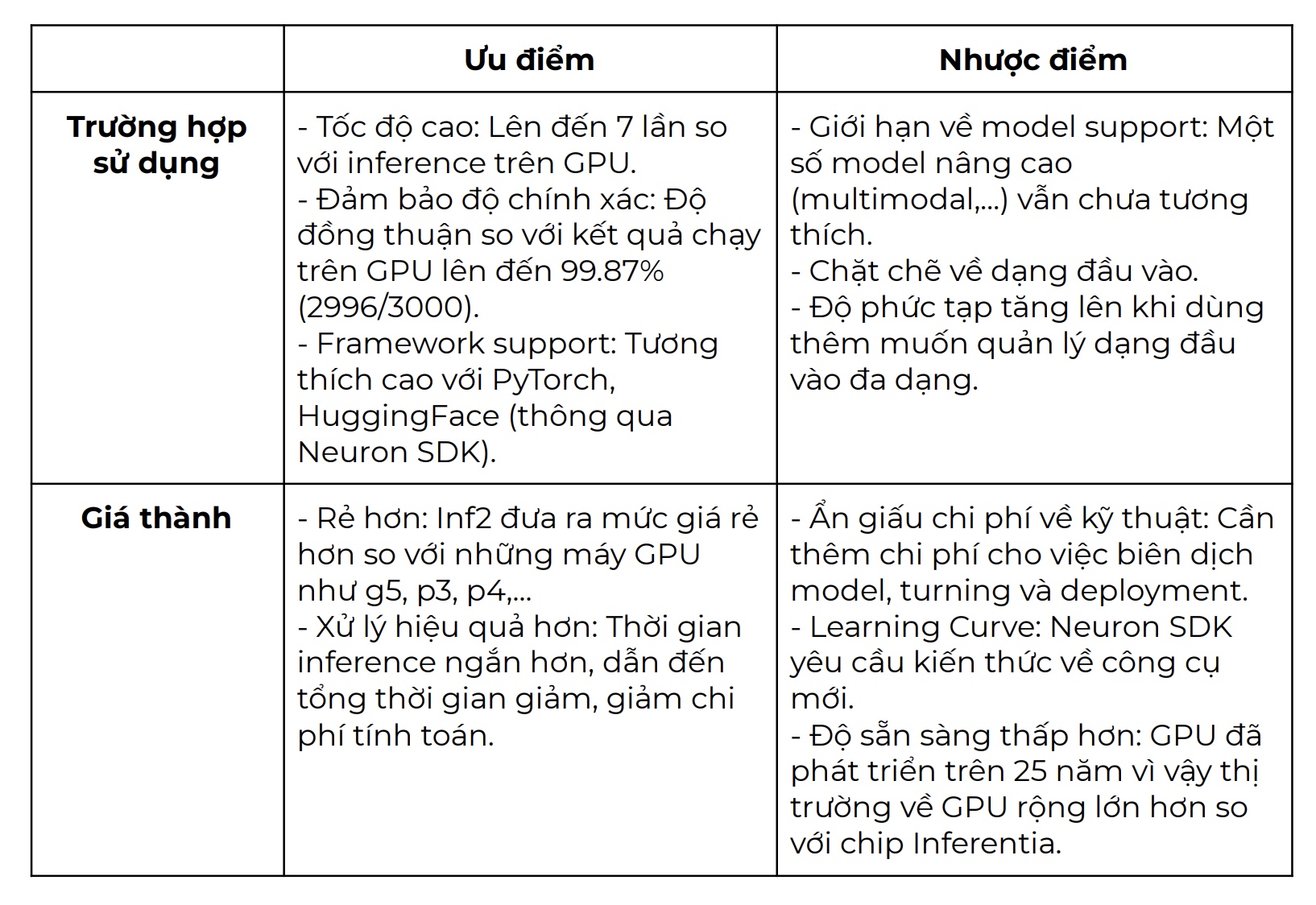
Tổng kết (so với kết quả model thử nghiệm ở trên):
Tham khảo:
- AWS Neuron SDK Documentation – https://docs.aws.amazon.com/neuron/latest
- HuggingFace Neuron Integration – https://huggingface.co/docs/optimum-neuron
- Github EVA02-CLIP – https://github.com/baaivision/EVA/tree/master/EVA-02