
Discord đang phát triển mạnh hơn so với chúng tôi dự kiến, song song với đó là sự tăng trưởng chóng mặt của nội dung mà người dùng tạo ra. Càng nhiều user sẽ càng có nhiều tin nhắn hơn. Riêng tháng 7 vừa rồi, nền tảng chúng tôi đã có khoảng 40 triệu tin nhắn mỗi ngày, tháng 12 là 100 triệu, và thời điểm blog này ra mắt thì con số đã lên đến 120 triệu. Ban đầu, đội ngũ Discord đã quyết định sẽ lưu trữ toàn bộ lịch sử cuộc trò chuyện của các người dùng để họ có thể xem lại bất cứ lúc nào, trên bất kỳ thiết bị nào. Có thể nói, đây là một kho dữ liệu khổng lồ đang gia tăng về cả velocity và kích thước nhưng vẫn cần đảm bộ độ available. Vậy chúng tôi đã xử lý vấn đề này như thế nào? Cassandra!
Chúng tôi đã sử dụng database nào?
Phiên bản đầu tiên của Discord được làm ra chỉ trong vòng chưa đầy hai tháng vào đầu năm 2015. Có thể cho rằng, một trong những database tốt nhất để duyệt dữ liệu một cách nhanh chóng là MongoDB. Chúng tôi chủ ý lưu trữ mọi thứ trên Discord lúc này trong một bản sao MongoDB duy nhất, tuy nhiên vẫn sắp xếp mọi thứ để thuận tiện cho việc di chuyển sang database mới (Chúng tôi không định sử dụng MongoDB lâu dài bởi sự phức tạp và tính không ổn định của nó). Đây cũng là một phần trong văn hóa làm việc của Discord: Luôn tìm giải pháp nhanh nhất để build sản phẩm nhưng cũng song song tìm kiếm phương pháp mới ổn định và tối ưu hơn.
Các tin nhắn được lưu trữ trong collection của MongoDB với bộ index là channel_id và created_at. Vào khoảng tháng 11 năm 2015, chúng tôi đã lưu trữ được 100 triệu tin nhắn và bắt đầu dự đoán được những vấn đề mới sẽ xuất hiện: Dữ liệu và index không thể fit đầy vào RAM và thời gian latency bắt đầu trở nên bất ổn định. Đã đến lúc Discord cần chuyển sang database phù hợp hơn.
Database nào là phù hợp hơn cả?
Trước khi quyết định chọn database mới, chúng tôi phải hiểu các mẫu read/write patterns và lý do tại sao giải pháp hiện tại đang gặp vấn đề.
- Chúng tôi nhanh chóng tìm ra lý do chính là phần reads đang cực kỳ ngẫu nhiên và tỷ lệ read/write là khoảng 50/50.
- Những server chủ yếu là voice chat hầu như không có tin nhắn hoặc chỉ có từ một đến hai tin nhắn trong vài ngày. Trong một năm, loại server này khó có nổi 1,000 tin nhắn. Vấn đề là mặc dù lượng tin nhắn rất ít nhưng người dùng vẫn sẽ rất khó khăn trong việc đọc lại tin nhắn. Chỉ cần trả lại 50 tin nhắn cho người dùng có thể dẫn đến nhiều lần tìm kiếm ngẫu nhiên trên ổ đĩa gây ra việc trục xuất bộ đệm của ổ đĩa.
- Những server private chủ yếu chat text message thì sở hữu một lượng tin nhắn khá khẩm hơn, khoảng từ 100 nghìn đến 1 triệu tin nhắn mỗi năm. Những người dùng của server này cũng chỉ có nhu cầu xem lại những tin nhắn được gửi trong thời gian gần. Tuy nhiên, vấn đề ở đây là do các máy chủ này thường chỉ có dưới 100 thành viên, do vậy tốc độ dữ liệu được yêu cầu sẽ thấp và khả năng cao sẽ không ở trong bộ đệm của ổ đĩa.
- Những public server, trái lại nhận được rất nhiều tin nhắn. Server này có đến hàng ngàn thành viên, gửi đi hàng ngàn tin nhắn trong một ngày và có thể dễ dàng đạt đến con số triệu trong một năm. Người dùng cũng thường xuyên xem những tin nhắn trong một giờ đồng hồ đổ lại, do đó dữ liệu thường nằm trong bộ đệm của ổ đĩa.
- Thời điểm đó, chúng tôi biết rằng trong năm tới mình cần phải bổ sung thêm nhiều cách để người dùng có thể tìm kiếm tin nhắn dễ dàng hơn như xem những ai đã mention bạn trong 30 ngày qua và truy cập đoạn hội thoại vào thời điểm đó, xem tin nhắn được ghim, tìm kiếm bằng đoạn văn bản,…
Bước tiếp theo, xác định các tiêu chí cần có!
- Khả năng mở rộng tuyến tính – Chúng tôi không muốn tìm kiếm giải pháp thay thế nào khác nữa trong tương lai cũng như phải sắp xếp lại dữ liệu một cách thủ công.
- Tự động sửa chữa – Developer chúng tôi cần được nghỉ ngơi, vậy nên Discord cần có nhiều tính năng tự sửa chữa khi xảy ra sự cố nhỏ.
- Ít phải maintain – Hoạt động tốt sau khi được thiết lập. Chúng tôi chỉ việc thêm các nodes khi có thêm dữ liệu mới.
- Khả năng hoạt động tốt – Chúng tôi cũng thích thử những công nghệ mới, nhưng không nên mới quá.
- Hiệu năng có thể dự đoán được – Chúng tôi thường bật cảnh báo khi 95% thời gian phản hồi API vượt quá 80ms. Chúng tôi cũng không muốn cache messages trong Redis hoặc Memcached.
- Không phải là một blob store – Việc ghi lại hàng ngàn tin nhắn mỗi giây sẽ không thể hoạt động trơn tru nếu chúng ta phải liên tục deserialize blobs và thêm dữ liệu vào dó.
- Nguồn mở – Chúng tôi muốn tự kiểm soát được vận mệnh của mình mà không muốn phụ thuộc vào bên thứ 3.
Cassandra là database duy nhất có thể đáp ứng được những tiêu chí trên. Chúng tôi chỉ cần thêm các node để scale up và nếu có mất đi vài node thì vẫn không ảnh hưởng đến ứng dụng. Các công ty khổng lồ như Netflix hay Apple có hàng ngàn node Cassandra. Dữ liệu liên quan được lưu trữ liên tục trên đĩa, cung cấp các tìm kiếm tối thiểu và phân phối dễ dàng xung quanh cluster. Nó được hỗ trợ bởi Datastax nhưng vẫn là một nguồn mở và hướng đến cộng đồng.
Sau khi đã lựa chọn, chúng tôi phải chứng minh được rằng Cassandra sẽ hoạt động tốt.
Mô hình hóa dữ liệu
Cách tốt nhất để mô tả Cassandra cho một người mới là nó được tổ chức dưới dạng KKV store. Hai K tạo nên khóa chính. K đầu tiên là khóa phân vùng sử dụng để xác định node nào có dữ liệu hoạt động và vị trí của nó trên đĩa. Phân vùng dữ liệu chứa nhiều hàng và một hàng trong phân vùng được xác định bởi K thứ 2 – khóa phân cụm. Khóa phân cụm đóng vai trò là cả khóa chính trong phân vùng và cách sắp xếp các hàng. Bạn có thể nghĩ về một phân vùng như một từ điển được sắp xếp. Các thuộc tính này kết hợp lại cho phép mô hình hóa dữ liệu rất mạnh mẽ.
Bạn có nhớ các tin nhắn được được lập chỉ mục (indexed) trong MongoDB bằng channel_id và created_at không? Channel_id trở thành khóa phân vùng vì tất cả các truy vấn hoạt động trên một kênh, nhưng created_at không tạo ra một khóa phân cụm tốt vì hai thông báo có thể có cùng thời gian tạo. May mắn thay, mọi ID trên Discord giống như những Snowflakes (chúng có thể sắp xếp theo thứ tự thời gian) , vì vậy chúng tôi có thể dùng nó để thay thế. Khóa chính đã trở thành (channel_id, message_id), trong đó message_id là một Snowflake. Điều này đồng nghĩa với việc khi tải kênh, chúng tôi có thể cho Cassandra biết chính xác vị trí quét phạm vi tin nhắn.
Đây là một lược đồ đơn giản hóa cho bảng thông báo của chúng tôi (đã lược bớt khoảng 10 columns)

Mặc dù các schema của Cassandra không giống một relational database nhưng chúng lại dễ dàng thay thế và không có bất kỳ tác động tạm thời nào lên hiệu năng. Chúng tôi có blob store (lưu trữ data không cấu trúc) tốt nhất và một relational store (lưu trữ data có quan hệ).
Khi chúng tôi bắt đầu import các tin nhắn hiện có vào Cassandra, ngay lập tức đã xuất hiện các cảnh báo trong logs nói rằng tìm thấy các phân vùng có kích thước vượt quá 100MB. Vậy là sao? Cassandra quảng cáo rằng nó có thể hỗ trợ các phân vùng lên tới 2GB! Hóa ra là nó có thể đạt được 2GB không đồng nghĩa với việc chúng ta nên làm thế, bởi các phân vùng lớn có khả năng gây áp lực lớn lên Cassandra trong quá trình nén, mở rộng cluster và hơn thế nữa. Một phân vùng lớn cũng sẽ khiến dữ liệu trong đó không thể phân phối xung quanh cluster. Bởi vậy, chúng tôi phải tìm cách ràng buộc kích thước của các phân vùng bởi chỉ một kênh Discord đơn lẻ cũng có thể tồn tại qua nhiều năm và tăng trưởng liên tục.
Chúng tôi quyết định phân chia lưu trữ tin nhắn theo thời gian (gọi là các bucket). Trước đó, chúng tôi đã xem xét các kênh lớn nhất trên Discord và xác định xem có khả năng lưu trữ tin nhắn của 10 ngày trong cùng một bucket dưới 100MB một cách thoải mái được không? Các bucket phải được tạo ra từ message_id hoặc timestamp.

Các khóa phân vùng Cassandra có thể được ghép, vì vậy khóa chính mới của chúng tôi đã trở thành ((channel_id, bucket), message_id).

Để truy vấn các tin nhắn gần đây trong kênh, chúng tôi đã tạo ra một bucket range từ thời điểm hiện tại tới channel_id (nó cũng là một snowflake và phải cũ hơn tin nhắn đầu tiên). Sau đó chúng tôi tuần tự truy vấn các phân vùng cho đến khi thu thập đủ các tin nhắn. Nhược điểm của phương pháp này là hiếm khi các Discord đang hoạt động phải truy vấn nhiều bucket cùng úc để thu thập đủ tin nhắn theo thời gian. Trong thực tế, điều này đã được chứng minh là ổn bởi với các Discord hoạt động có đủ tin nhắn, chúng thường được tìm thấy trong phân vùng đầu tiên và chiếm đa số.
Việc nhập tin nhắn vào Cassandra không gặp trở ngại nào và chúng tôi đã sẵn sàng để thử với môi trường production.
Launching không thành công
Quá trình đưa một hệ thống mới lên production luôn khiến nhiều người lo lắng, bởi vậy, hãy cố gắng test và tránh ảnh hướng tới người dùng. Chúng tôi setup code để double read/write lên MongoDB và Cassandra.
Ngay sau khi launching, chúng tôi bắt đầu nhận được thông báo lỗi từ bug tracker: Author_id lỗi null. Tại sao lại có lỗi null trong khi đây là trường bắt buộc?
Tính nhất quán
Cassandra là cơ sở dữ liệu AP ưu tiên tính khả dụng thay vì tính nhất quán, và đây là điều chúng tôi đang tìm kiếm. Đây là mô hình anti-pattern để đọc trước khi ghi trong Cassandra. Do đó Cassandra thực hiện UPSERT (INSERT … neu da ton tai thi UPDATE) ngay cả khi chỉ cung cấp một số cột nhất định. Bạn cũng có thể ghi vào bất kỳ node nào và nó sẽ tự động giải quyết các xung đột bằng cách sử dụng lần ghi cuối cùng trên mỗi cột. Vì vậy, tại sao lại xảy ra lỗi như vậy?

Giả định xảy ra trường hợp có người dùng chỉnh sửa một tin nhắn cùng lúc với một người dùng khác xóa tin nhắn đó, chúng tôi kết thúc bằng một row thiếu tất cả dữ liệu ngoại trừ primary key và text vì tất cả các xử lý ghi của Cassandra đều là “UPSERT”. Có hai giải pháp khả thi để xử lý vấn đề này:
- Ghi lại toàn bộ tin nhắn ở lần chỉnh sửa. Điều này có khả năng phục hồi các tin nhắn đã bị xóa nhưng cũng sẽ làm tăng khả năng xung đột với các xử lý ghi đồng thời vào các cột khác.
- Xác định tin nhắn bị hỏng và xóa khỏi cơ sở dữ liệu.
Chúng tôi lựa chọn cách thứ 2, chọn một cột được yêu cầu (trong trường hợp này là Author_id) và xóa tin nhắn nếu nó là null.
Khi giải quyết vấn đề này, chúng tôi nhận thấy nhóm đã làm việc kém hiệu quả với các xử lý ghi. Cassandra sở hữu tính nhất quán cao nên nó không thể xóa dữ liệu ngay lập tức mà sẽ sao chép phần dữ liệu bị xóa sang các nodes khác và sao chép ngay cả khi các node khác tạm thời không khả dụng. Cassandra thực hiện điều này bằng cách xem phần dữ liệu xóa dưới dạng 1 “tombstone”(bia mộ). Khi đọc, nó sẽ lướt qua các “tombstones”. “Tombstones” tồn tại trong một khoảng thời gian có thể định cấu hình (mặc định là 10 ngày) và bị xóa vĩnh viễn trong quá trình nén khi thời gian đó hết hạn.
Xóa một column và ghi null vào một column cũng tương tự như vậy. Cả hai đều tạo ra “tombstone”. Vì tất cả các xử lý ghi trong Cassandra đều là UPSERT đồng nghĩa với việc bạn đang tạo ra tombstone ngay từ lần ghi null lần đầu tiên. Trong thực tế, toàn bộ message schema của chúng tôi chứa 16 columns, nhưng trung bình 1 message chứa 4 giá trị. Phần lớn thời gian chúng tôi đã ghi 12 tombstones vào Cassandra mà chẳng mang lại lợi ích gì. Giải pháp cho vấn đề này rất đơn giản: chỉ ghi các giá trị không null vào Cassandra.
Hiệu năng
Cassandra được biết đến với khả năng ghi nhanh hơn đọc và chúng tôi đã quan sát thấy điều đó. Cassandra ghi với tốc độ dưới 1 mili giây và đọc dưới 5 mili giây. Điều này được duy trì bất kể dữ liệu nào đang được truy cập và hiệu năng vẫn ổn định trong suốt một tuần thử nghiệm. Không có gì đáng ngạc nhiên và chúng tôi đã có được kết quả theo đúng mong đợi ban đầu.
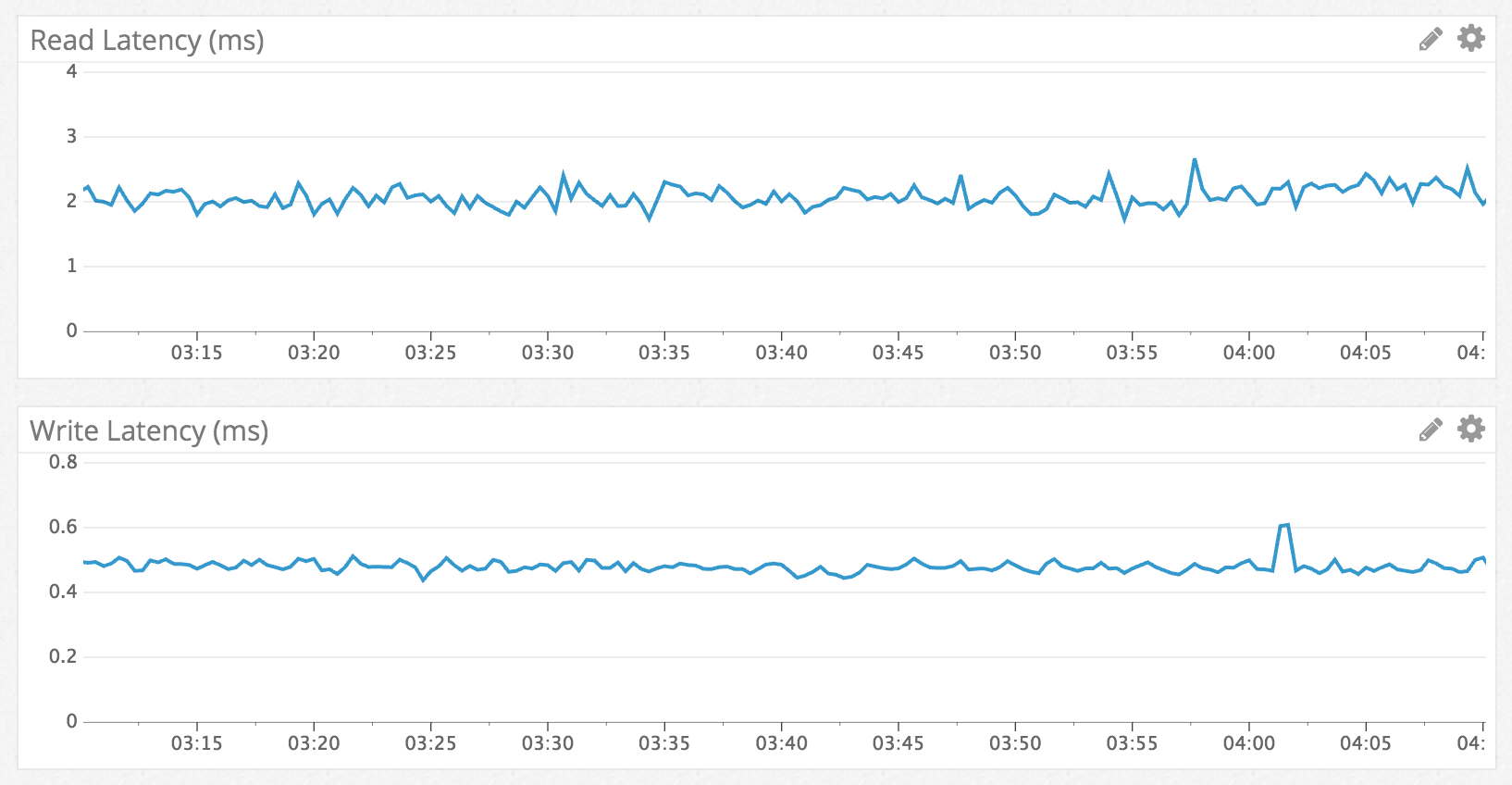
Read/Write Latency via Datadog
Để phù hợp với hiệu năng đọc nhanh và nhất quán, dưới đây là một ví dụ về truy cập tin nhắn từ hơn một năm trước trong một kênh có hàng triệu tin nhắn:
Vấn đề phát sinh ngoài dự kiến (Big Surprise)
Cassandra hoạt động khá suôn suôn sẻ nên chúng tôi đã quyết định triển khai nó làm cơ sở dữ liệu chính và loại bỏ MongoDB trong vòng một tuần. Cassandra tiếp tục hoạt động hoàn hảo trong khoảng 6 tháng và bỗng dưng đến một ngày không response nữa.
Chúng tôi nhận thấy Cassandra đang chạy tác vụ 10 giây Garbage Collector liên tục, nhưng chúng tôi không biết tại sao. Chúng tôi bắt đầu nghiên cứu và tìm thấy một kênh chat Discord mất 20 giây để tải. Puzzles & Dragons Subreddit Discord public Discord server chính là thủ phạm. Chúng tôi bắt tay ngay vào kiểm tra và nhận ra channel đó chỉ có 1 tin nhắn. Tại thời điểm đó, mọi việc đã rõ ràng khi mà admin đã xóa hàng triệu tin nhắn bằng API của chúng tôi, chỉ để lại 1 tin nhắn duy nhất trong channel.
Hẳn bạn có còn nhớ cách Cassandra xử lý xóa bằng cách sử dụng “tombstones” (được đề cập trong phần Tính nhất quán). Khi người dùng tải channel, mặc dù chỉ có 1 tin nhắn, Cassandra vẫn quét qua hàng triệu “tombstones” (tạo rác nhanh hơn khả năng xử lý gom rác của JVM).
Chúng tôi đã giải quyết vấn đề này bằng cách:
- Hạ thấp vòng đời của “tombstones” từ 10 ngày xuống còn 2 ngày và chạy Cassandra repairs (một quy trình chống entropy) mỗi đêm trên message cluster.
- Thay đổi query code để theo dõi các bucket rỗng và tránh để chúng xuất hiện trong tương lai. Điều này có nghĩa là nếu người dùng thực hiện query này một lần nữa thì tệ nhất là Cassandra sẽ chỉ quét những bucket gần đây nhất.
Tương lai
Chúng tôi hiện đang chạy một cluster 12 node với hệ số sao chép là 3 và sẽ tiếp tục thêm các Cassandra node mới khi cần. Chúng tôi tin rằng cách này sẽ tiếp tục hoạt động hiệu quả trong một thời gian dài, tuy nhiên khi Discord tiếp tục phát triển, chúng tôi buộc phải nghĩ về nơi lưu trữ hàng tỷ tin nhắn của mình. Netflix và Apple đang chạy các cluster gồm hàng trăm node khiến chúng tôi tự nhủ liệu mình có đang lo nghĩ quá xa.Tuy nhiên, chúng tôi đã chuẩn bị một số ý tưởng cho tương lai:
Ngắn hạn
- Nâng cấp message cluster từ Cassandra 2 lên Cassandra 3. Cassandra 3 có định dạng lưu trữ mới có thể giảm kích thước lưu trữ hơn 50%.
- Các phiên bản mới hơn của Cassandra có thể xử lý nhiều dữ liệu hơn trên một node. Chúng tôi hiện lưu trữ gần 1TB dữ liệu nén trên mỗi node. Chúng tôi tin rằng mình có thể giảm số lượng node trong cluster một cách an toàn bằng cách tăng dữ liệu nén trên mỗi node lên 2TB.
Dài hạn
- Thử sử dụng Scylla, một cơ sở dữ liệu tương thích với Cassandra được viết bằng C ++. Trong các hoạt động bình thường, các node Cassandra không sử dụng quá nhiều CPU, tuy nhiên vào những giờ cao điểm khi chúng tôi chạy repair,, chúng trở nên bị ràng buộc CPU và thời lượng bị tăng lên với lượng dữ liệu được ghi từ lần sửa chữa trước. Scylla quảng cáo có thể làm giảm thời gian sửa chữa một cách đáng kể.
- Xây dựng hệ thống để lưu trữ các kênh không sử dụng thành các tệp phẳng trên Google Cloud Storage và tải chúng về theo yêu cầu. Chúng tôi muốn tránh làm điều này và không cũng không nghĩ mình sẽ phải làm điều đó.
Kết luận
Đã được hơn một năm kể từ khi chúng tôi thực hiện chuyển đổi và mặc dù vấp phải “Big Surprise”, nhưng mọi thứ đã được giải quyết. Lượng tin nhắn tăng từ hơn 100 triệu lên hơn 120 triệu tin nhắn mỗi ngày và hiệu năng vẫn được duy trì ổn định. Với thành công này, chúng tôi đã chuyển phần còn lại của dữ liệu production của mình sang Cassandra và đây cũng được xem là một thành công.
Tiếp theo sau bài viết này, chúng tôi sẽ chia sẻ cách tìm kiếm một tin nhắn trong hàng tỷ tin nhắn.
Tác giả: Stanislav Vishnevskiy
Link bài viết gốc: tại đây
Dịch và chỉnh sửa: Ly Nguyễn, Vân Phạm, Anh Đức